
Se você trabalha com grandes bases de dados transacionais, sofre com dashboards lentos e pensa que DirectQuery (DQ) é a solução dos seus problemas então você está no local certo! Explicaremos porque você deve evitar esse modo de conexão no Power Bi!
O Power BI possui 3 modos de conexão com a fonte de dados: Import, DirectQuery e LiveConnection.
Apenas para dar um overview… LiveConnection é uma conexão dinâmica a um modelo do Analysis Services (SSAS ou AAS). É tão performático quanto Import porque faz uso da mesma engine por trás (modelo tabular).
A batalha de hoje será entre Import e DirectQuery, ok?!

Clique Aqui para iniciar sua jornada rumo ao domínio do Power BI.
Cenário
Imagine a seguinte situação: seus dados estão num banco de dados SQL Server. Você precisa se conectar nesse banco para construir seu relatório em PBI, beleza?!
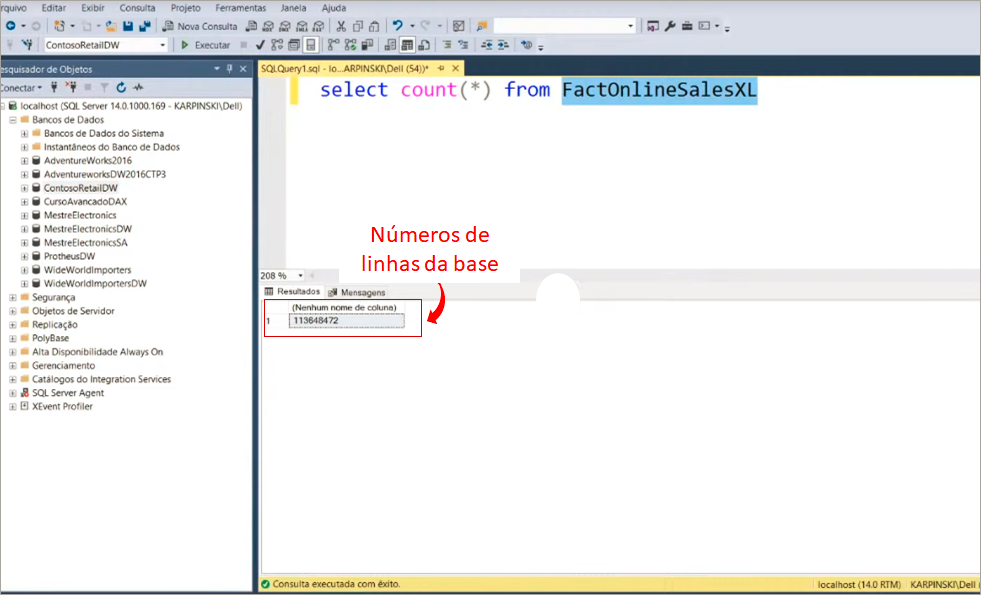
Realizaremos uma conexão no banco de dados ContosoRetailDW e utilizaremos a tabela FactOnlineSalesXL. Dê uma olhada no tamanho da base utilizando o Microsoft SQL Server Management Studio:
No PBI Desktop, assim que você selecionar Banco de Dados SQL Server, aparecerá essas duas opções de conexão:
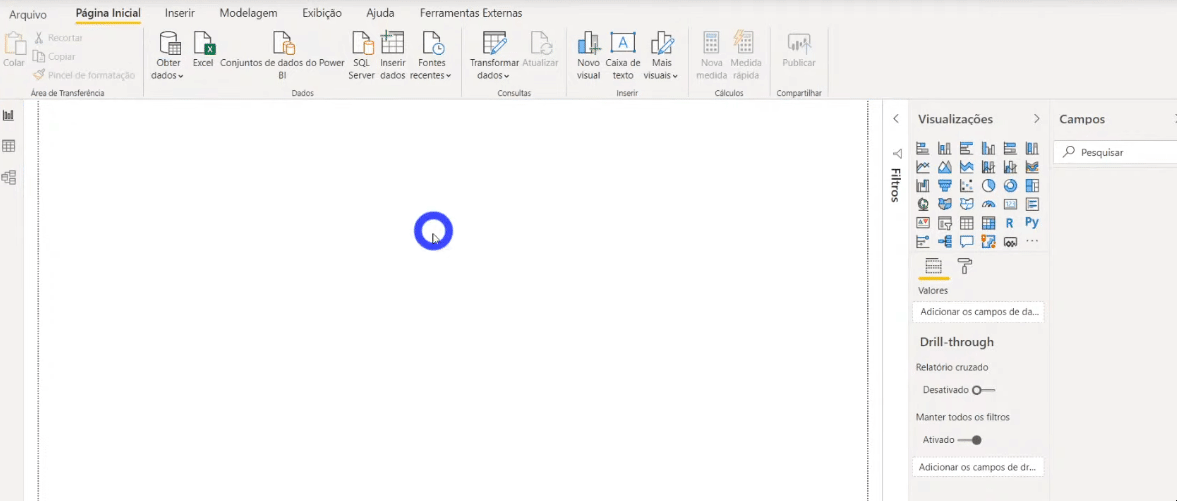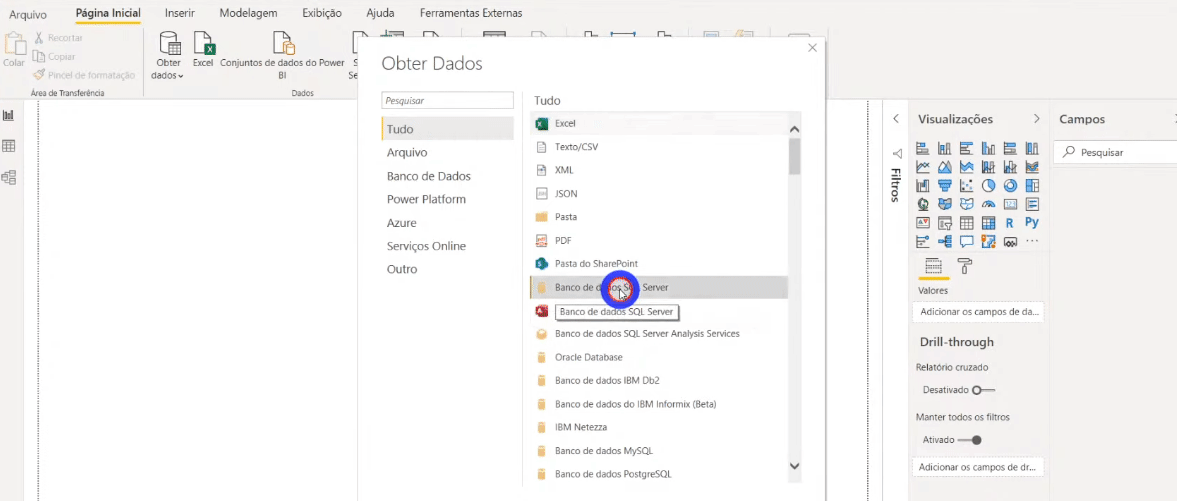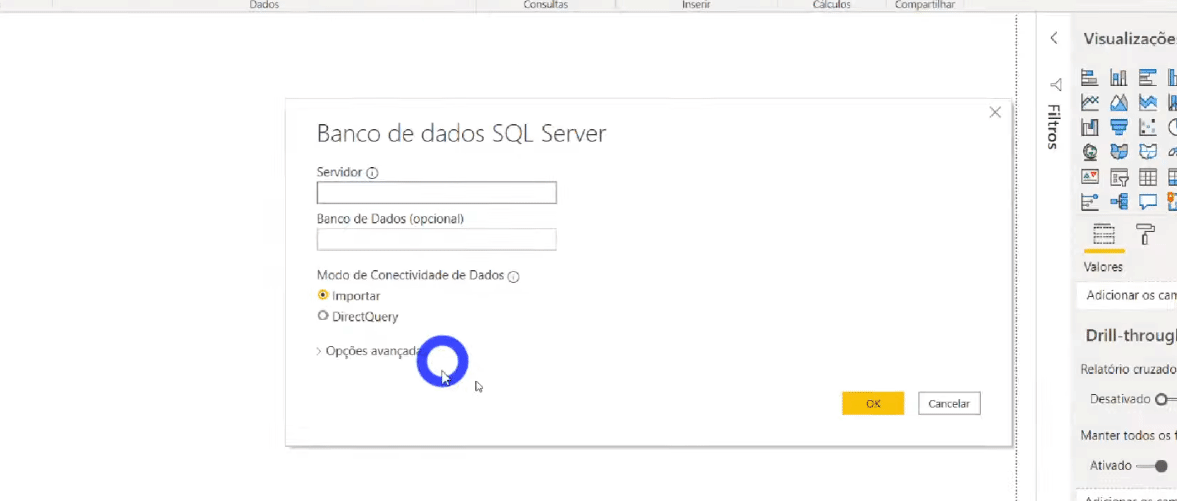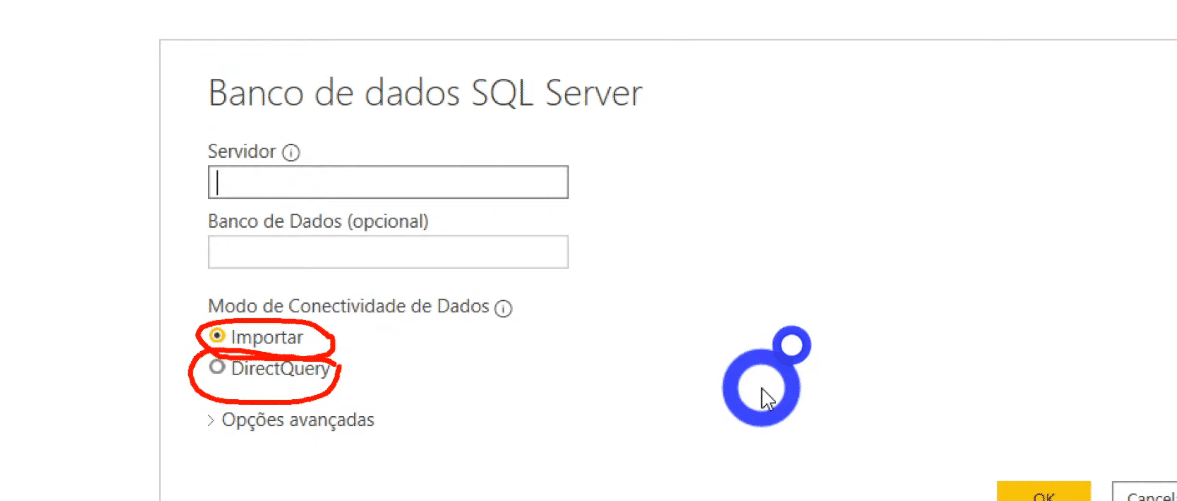
Caso não tenha assistido à Live #26 pode ser que você esteja assim:

Calma! Vamos mostrar a diferença entre esses dois modos de conexão e no final desse artigo você não terá mais dúvidas sobre isso!
Clique Aqui para aprender mais sobre SQL, a principal linguagem de programação utilizada pelas empresas e se destacar no mercado de trabalho.
Import
Nesse tipo de conexão os dados são importados para o PBI Desktop e são armazenados na memória do seu computador. Quando o relatório for publicado, os dados passarão a ficar na memória do servidor da Microsoft (a tal da Nuvem).
Esse modo de conexão garante uma ótima perfomance durante a análise de dados porque ao importá-los o PBI realiza uma importante compressão em cada coluna do modelo. E depois, salva cada coluna comprimida em um espaço diferente na memória. Ou seja, os dados ficam cacheados na memória do computador em que você estiver desenvolvendo o relatório.
Isso gera duas consequências: o arquivo .pbix ficará grande e a atualização de dados demorará mais para ser concluída. Mas veja bem: isso não deve ser uma desculpa para usar o DirectQuery! Veremos em breve como contornar esses problemas!
Performance usando Import
Vamos realizar o primeiro teste selecionando o modo de conexão Import.
Após importar a tabela FactOnlineSalesXL para dentro do PBI Desktop você vai levar um tempinho para carregar todas as linhas… Tenha paciência e tome um café enquanto espera… E assim que terminar salve o arquivo .pbix, ok?! Ah, quando salvamos ele ficou com 586 MB!

O modelo desse nosso exemplo é aquele basicão: Star schema.
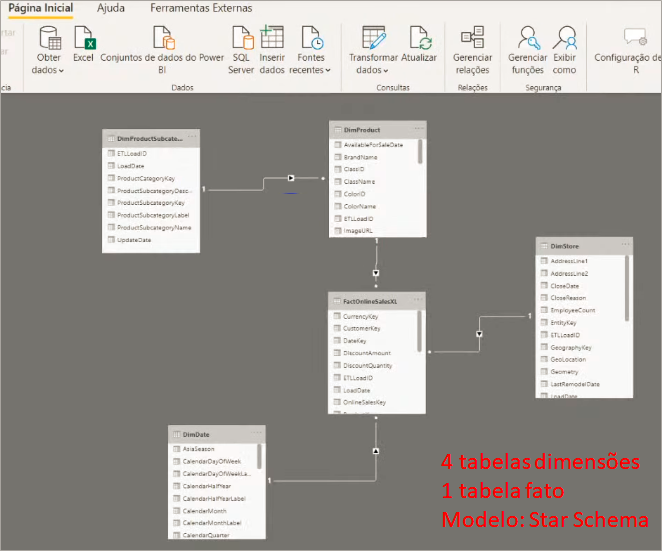
Deixei uma página em branco e uma outra com dois visuais no relatório para poder analisar a performance de forma mais consistente (faremos o mesmo com Direct Query).
Utilizaremos o Performance Analyzer para medir o tempo de processamento necessário para criar ou atualizar os elementos de relatório iniciados como resultado de qualquer interação do usuário que resulte na execução de uma consulta.
Para usá-lo basta ir em Arquivo → Exibição → Performance Analyzer. Deixe a página Blank selecionada, clique em Iniciar gravação e mude para a segunda página (Import). Veja:
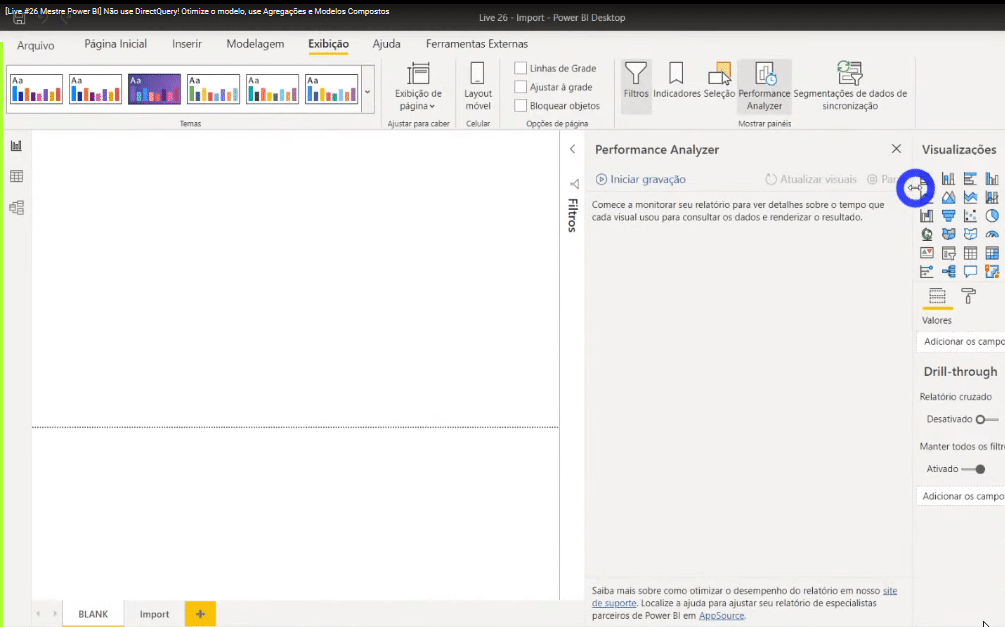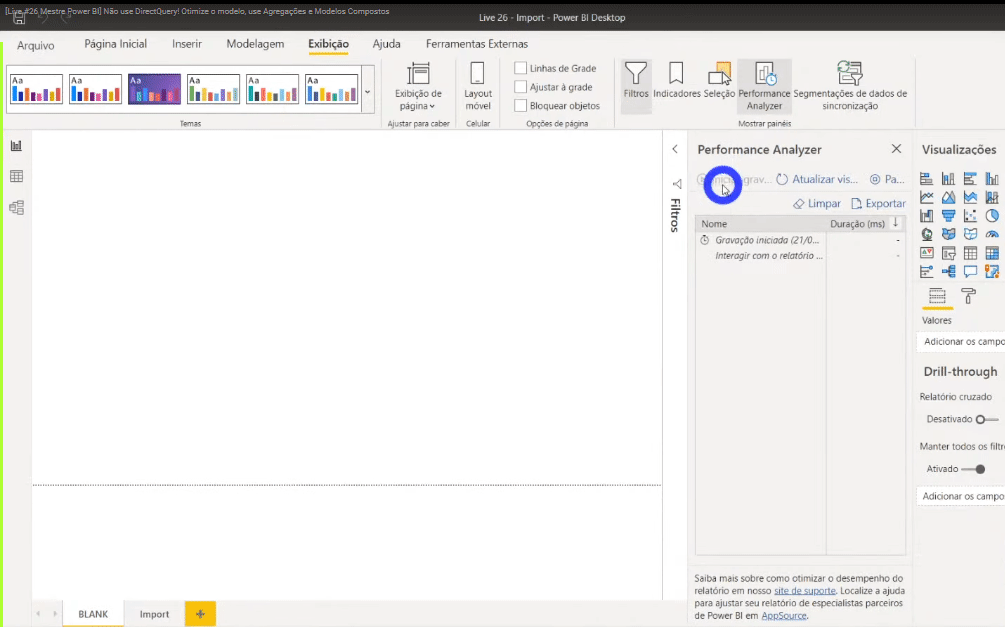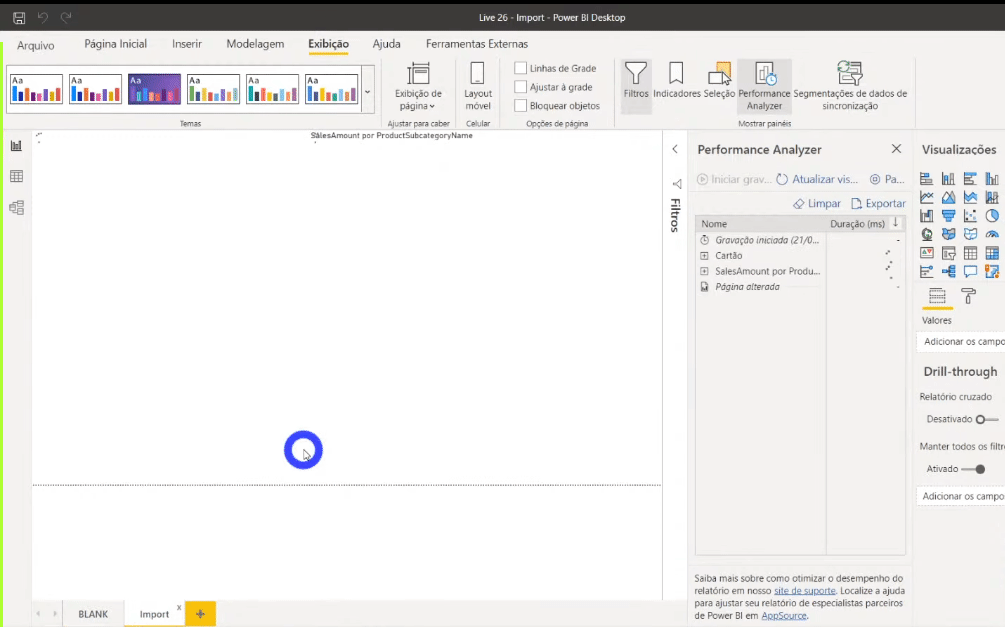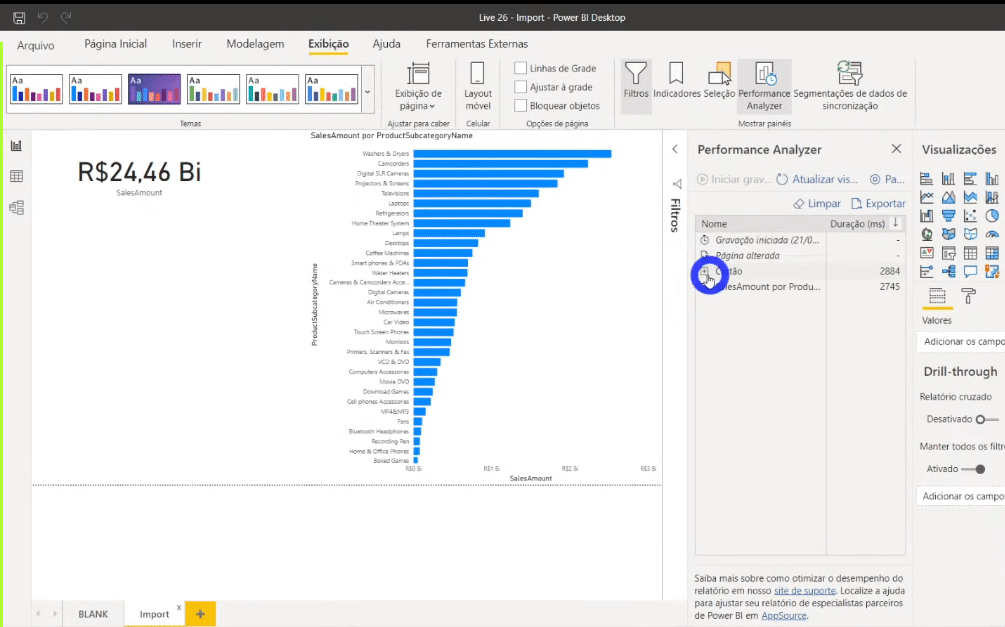
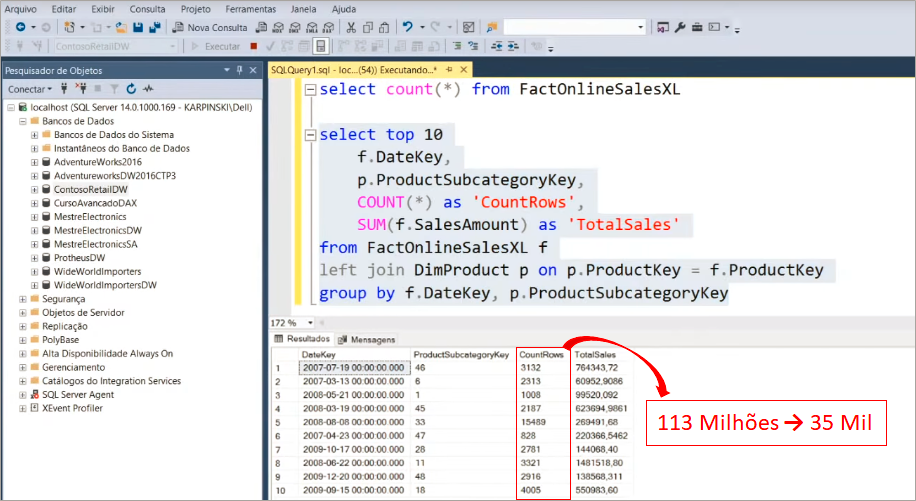
Lembra daquelas 113 milhões de linhas? Só levou cerca de 3 segundos no total para processar tudo. Super rápido! Porém ao salvarmos o relatório, o arquivo .pbix ficou com 586 Mb!
DirectQuery
Ao contrário do modo Import, ao usar DirectQuery você não estará importando os dados para o arquivo .pbix, ou seja, eles vão continuar apenas na fonte (servidor que contém o banco de dados conectado) e você realizará consultas nessa fonte durante a análise de dados.
Esse modo de conexão funciona assim: se você realizar um filtro em um gráfico do relatório isso será traduzido em uma query. Essa query será enviada para sua fonte de dados e processada e, por fim, os dados retornarão atualizados para seu PBI. Portanto, toda a pressão e carga ficarão sob responsabilidade do servidor onde estão armazenados seus dados.
A principal vantagem do modo de conexão através do DQ é que os dados estarão sempre atualizados – já que para cada interação o PBI buscará os dados diretamente na fonte. Outra vantagem é que o arquivo .pbix ficará menor já que não os dados não estarão armazenados lá – só ficam os metadados nesse arquivo.
Esse modo de conexão tem uma baixa performance para o usuário final que utilizará seu relatório e além disso, se o banco de dados que você se conectar estiver sendo utilizado para outros fins poderá haver concorrência no seu servidor e impactar não só a análise de dados no Power Bi mas também o uso de outros usuários que dependem desse servidor e possivelmente até derrubá-lo. Já imaginou que tragédia?!
Resumindo, os principais pontos que costumam levar as pessoas a usarem o DirectQuery são:
- Grande volume de dados – onde supostamente o modo Import não daria conta;
- Necessidade de dados em tempo real
Performance usando DirectQuery
Vamos nos conectar à nossa base utilizando novamente a seleção: Banco de Dados SQL Server.
O arquivo .pbix tem as mesmas páginas do teste que fizemos anteriormente (usando Import), ok?
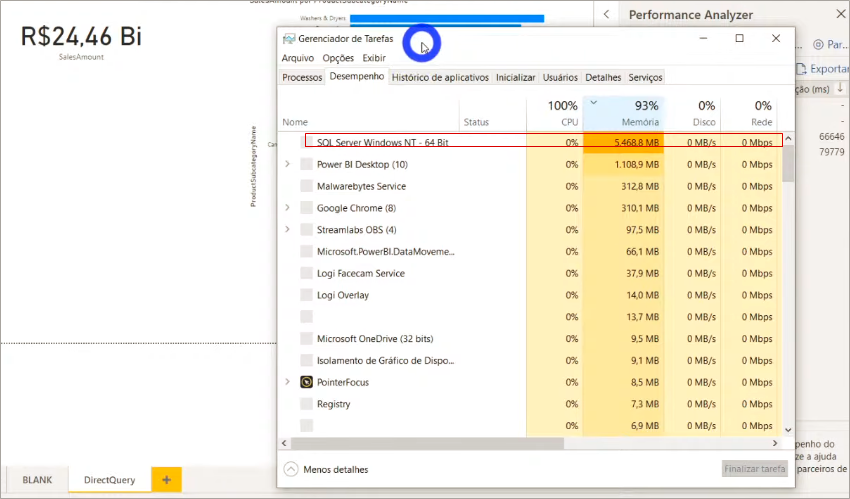
Utilizaremos o Performance Analyzer para medir o tempo de processamento novamente. Dessa vez se prepare psicologicamente porque vai demorar para processar! Veja o consumo de memória do SQL Server enquanto processamos (nesse exemplo o “servidor” é a minha própria máquina):
Ah, apenas para registrar: quando salvamos o arquivo .pbix ele ficou com 52 Kb!
O tempo total para processamento foi aproximadamente 1 minuto (no modo Import eram 3 s, lembra?). Você pode até estar considerando esse tempo ‘razoável’ mas lembre-se: tínhamos apenas 1 gráfico de barras e um cartão nessa página do relatório! Já imaginou um painel completo?! O usuário vai desistir de usar o relatório porque não aguentará esperar tanto tempo para cada análise/interação que fizer.
Conseguiu perceber que o motivo “tenho uma base base grande” não é suficiente para usar exclusivamente o DirectQuery como modo de conexão?
Soluções
Antes de falarmos sobre as soluções precisamos deixar claro o seguinte:
É fundamental que a conexão seja realizada em um Data warehouse e não no banco de dados de produção!
Principalmente quando pensamos em DirectQuery! Caso contrário você estará concorrendo com o banco de produção a todo momento. E como já mencionado: você pode derrubar o servidor!
Uma queixa muito comum de ouvir é:
Meu relatório está lento, o que pode ser?
Primeiro você precisará identificar onde está a lentidão. As opções são:
- No Power Query e atualização dos dados
- No modelo de dados (.pbix está muito grande – acima de 500 MB)
- Medidas Dax (falaremos sobre perfomance em DAX em outro artigo)
Agora eu te pergunto: qual desses casos é o mais crítico?
Se você respondeu 1, vamos pensar juntos… Quando você atualiza os dados no PBI, você costuma fazer isso que horas?! Quando você está desenvolvendo? Quando os usuários estão fazendo análises? Acredito que não, certo?! Geralmente atualizações são programadas para ocorrerem em horários não comerciais, como de madrugada, finais de semana… Então não tem problema se essa atualização levar 30 ou 40 minutos, beleza?!
Lembre-se: você deve pensar no usuário final desse relatório! Quem vai analisar!
Regra de ouro: o Power Bi precisa ser rápido para quem vai analisar os dados, e não para você que está desenvolvendo!
Calma! Não vou só falar isso e sair correndo! Há formas de deixar o desenvolvimento rápido sim!
Para que o desenvolvimento seja rápido, você precisa garantir duas coisas:
- Máquina legal: acima de 8GB de memória RAM e disco SSD
- Importar apenas uma amostra dos dados durante o desenvolvimento (filtrar linhas)
Tenho certeza que a dica 2 vai mudar sua vida daqui pra frente! Faremos isso através de um recurso chamado Atualizações incrementais.
Nosso objetivo é resolver dois problemas: desenvolvimento lento e demora na atualização.
Atualização incremental
Antes de mostrar o passo a passo você precisa saber que para utilizar esse recurso é necessário ter no mínimo a conta PRO.
Criação de parâmetros
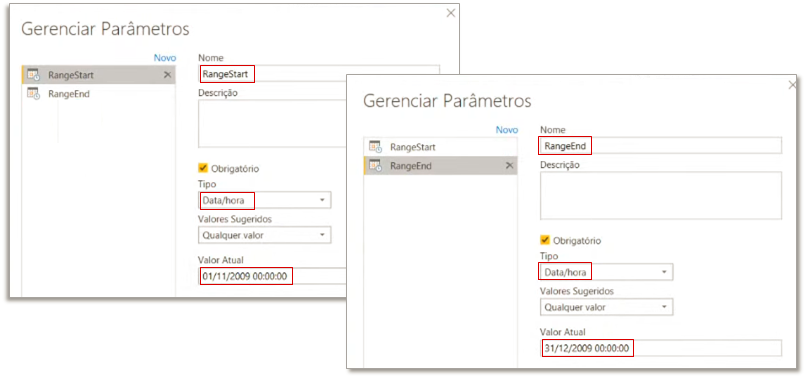
Precisaremos criar dois parâmetros: RangeStart e RangeEnd. Para isso, abra o Power Query → Página inicial → Gerenciar Parâmetros → Novo Parâmetro e depois preencha os campos conforme mostra a figura abaixo:
Filtro em linhas da tabela fato
O próximo passo será filtrar as linhas da tabela fato (é a tabela que tem 113 milhões de linhas, lembra?!) utilizando esses parâmetros que acabamos de definir. Devemos filtrar a coluna DataKey da tabela FactOnlineSalesXL, veja:
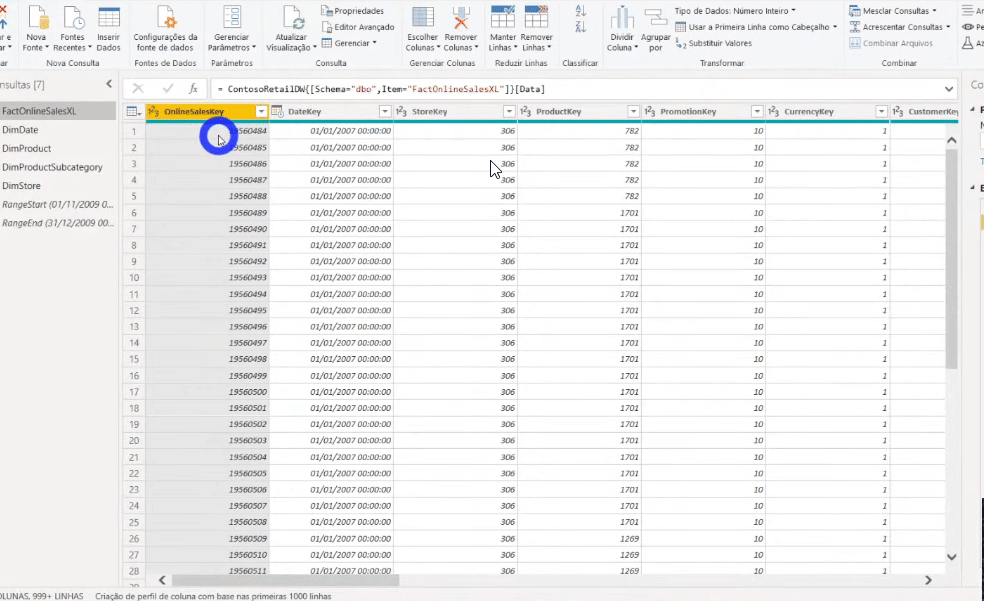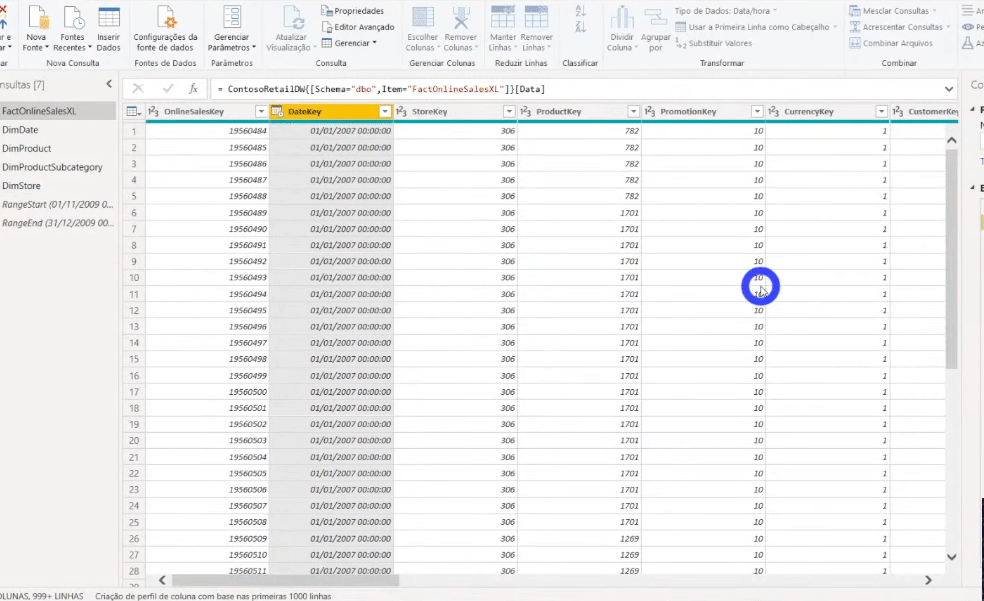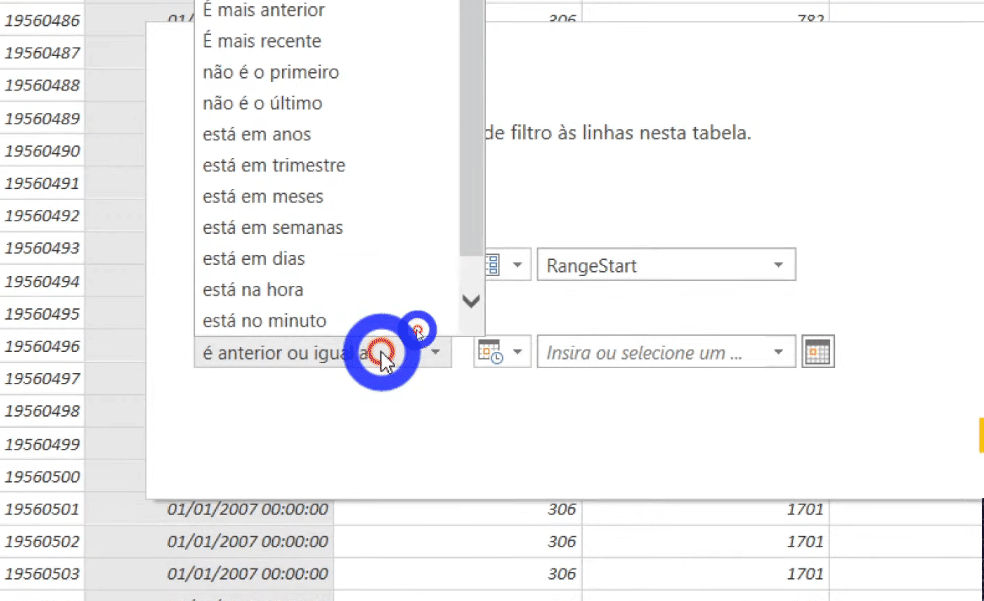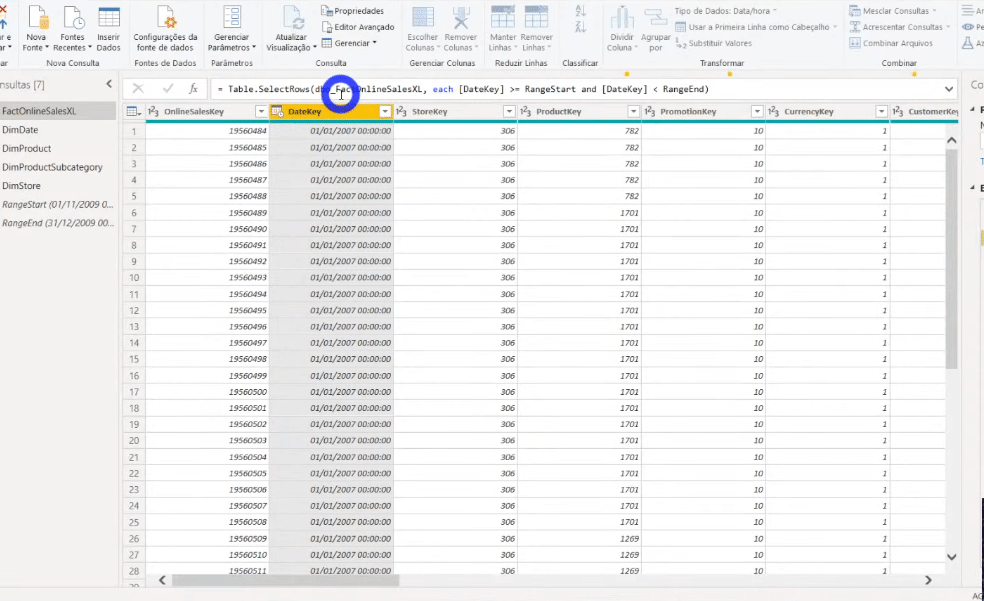
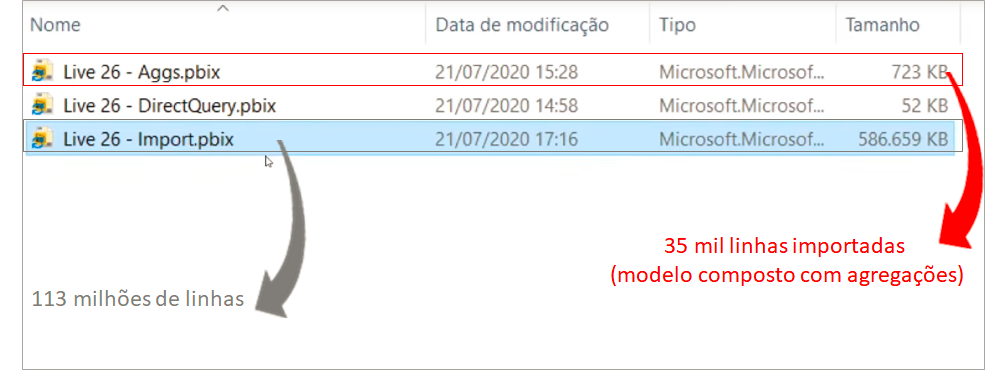
Após aplicar esse filtro reduzimos para 8 milhões de linhas nossa tabela fato. Saímos de um arquivo .pbix de 586 MB e agora estamos com 31 MB!
Configurando a atualização incremental
Agora precisamos indicar para o Power Bi que queremos atualizar somente os dois últimos meses da tabela fato e não a base toda. Para configurar a atualização incremental basta clicar com o botão direito do mouse em qualquer tabela do painel Campos e seguir o passo a passo da imagem:
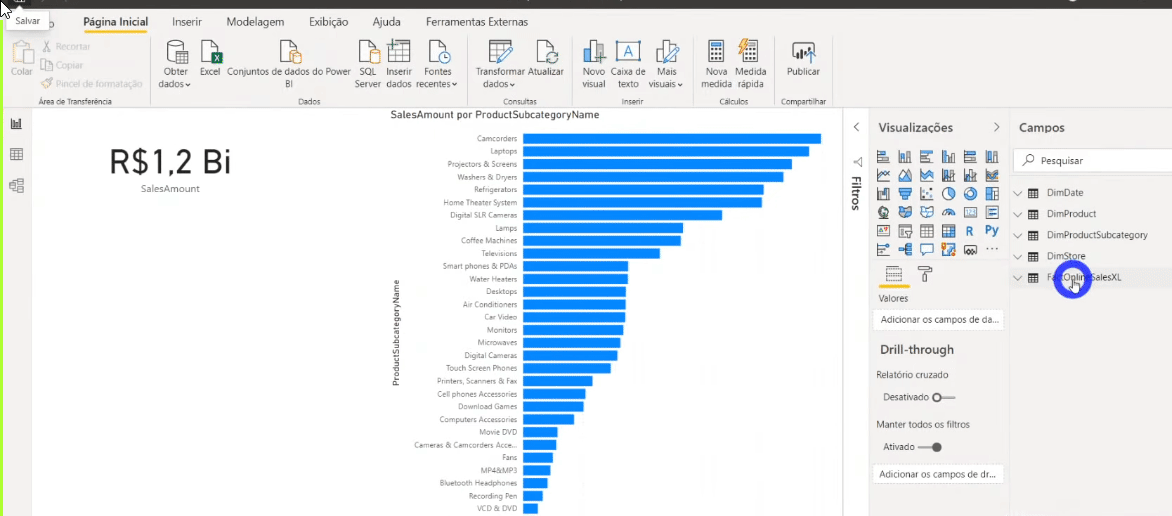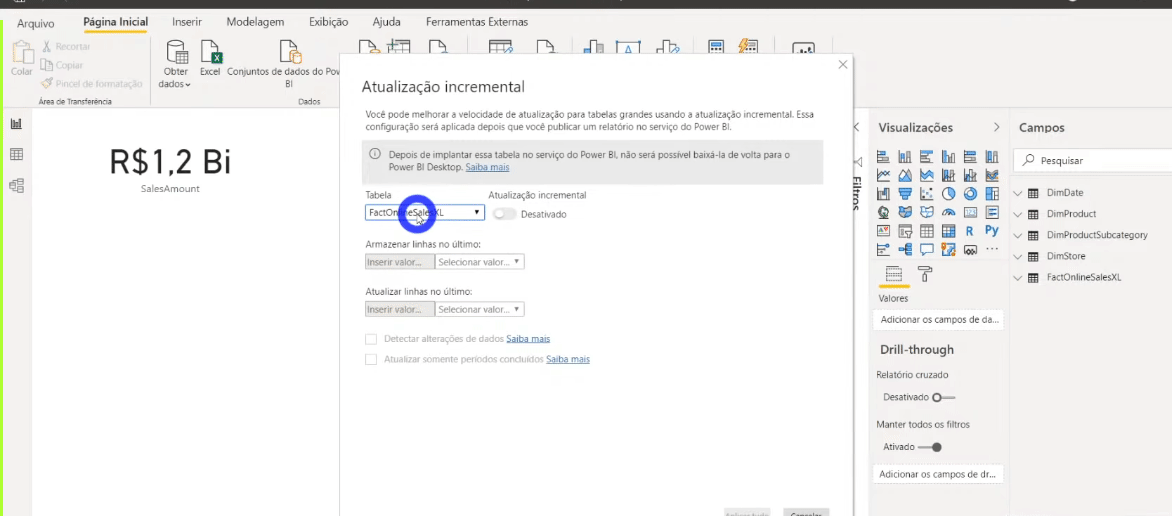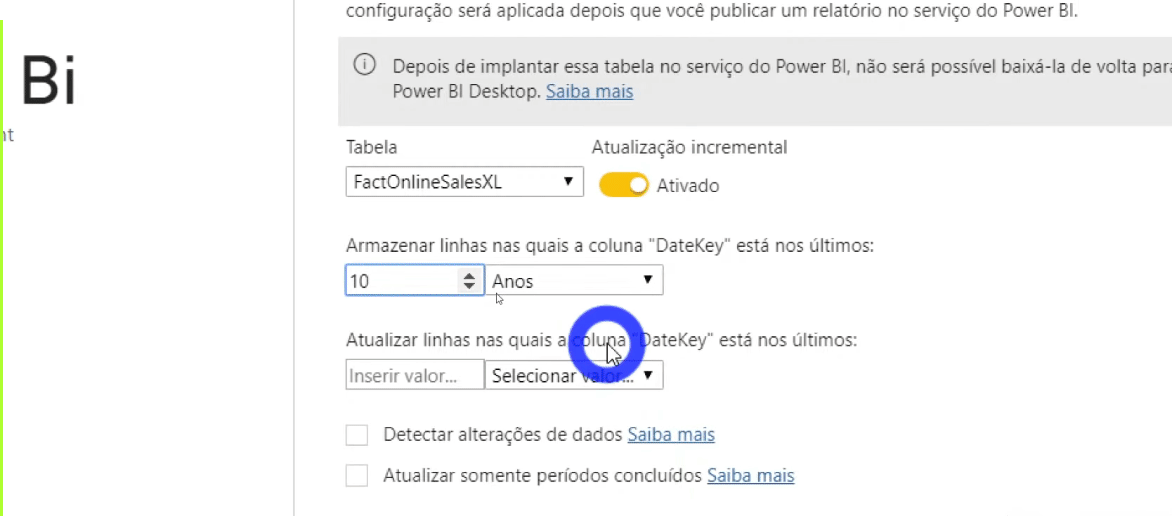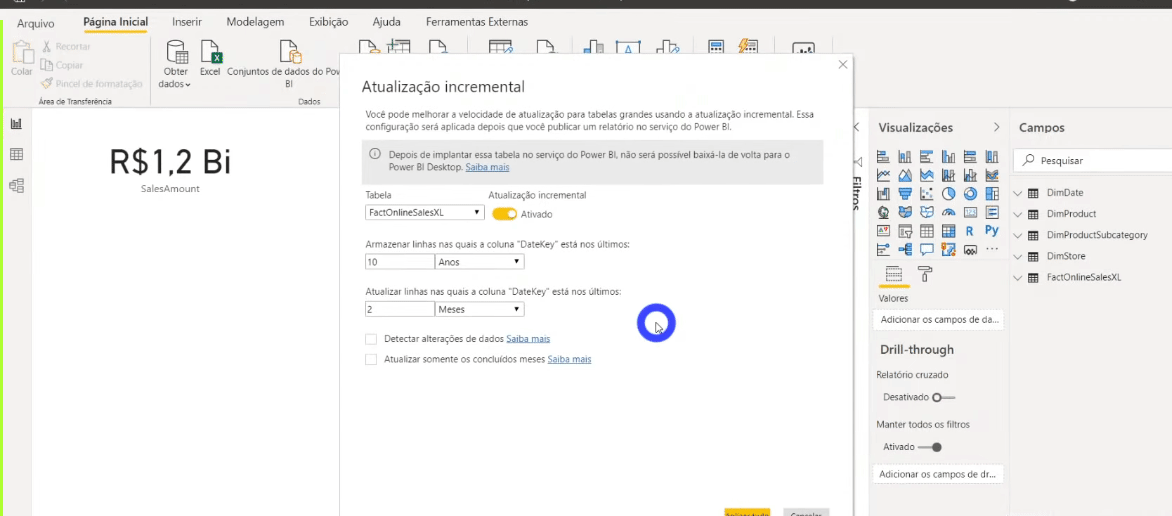
Você pode estar com dúvida sobre porque criamos aqueles dois parâmetros fixos (RangeStart e RangeEnd)… Eles estão fixos naquelas datas de início e fim (2 meses de duração) para fins de desenvolvimento. RangeStart e RangeEnd ficarão dinâmicos quando publicarmos o relatório no PBI Online!
Lembrete:
O Power Bi Desktop é seu ambiente de desenvolvimento. Jamais importe todas as linhas para desenvolver, é um desperdício absurdo de recurso e uma perda de tempo gigante. A base precisa estar completa apenas no relatório publicado no serviço online.
Se tiver alguma dúvida sobre isso acesse esse link para ler a documentação da Microsoft: https://docs.microsoft.com/pt-br/power-bi/admin/service-premium-incremental-refresh
Por hora resolvemos o problema “desenvolvimento lento” e “demora na atualização” porque reduzimos o tamanho do arquivo .pbix e configuramos o PBI para atualizar apenas os últimos dois meses.
Porém, para o usuário final – que acessará o relatório publicado no PBI Online, ainda temos aqueles quinhentos e poucos MB de arquivo (base completa) e o modelo ainda não será tão performático para ele.

Então, vamos resolver o problema de má performance no serviço online com as seguintes dicas:
- Importe apenas tabelas e colunas que realmente sejam necessárias para a análise: comece pequeno e depois vá crescendo conforme real necessidade do cliente.
- Utilize a modelo Star schema, com campos descritivos apenas nas dimensões. Ex: nomes do produtos na tabela fato e na tabela dimensão.
Lembrete:
O principal inimigo da performance é a quantidade de colunas e a cardinalidade das colunas (quantidade de valores distintos).
Para saber quais colunas e tabela otimizar, você deve usar o VertiPaq Analyzer (que está dentro do DAX Studio).
Identificando colunas e tabelas para otimizar
DAX Studio é uma ferramenta gratuita e está disponível para download neste link. Assim que abrir o programa aparecerá essa janela de navegação para que você selecione o arquivo .pbix que deseja analisar (ele deve estar aberto):
Ao clicar na guia Advanced e selecionar View Metrics você conseguirá ver exatamente o quanto de memória cada coluna do seu modelo ocupa! Veja que no nosso exemplo a coluna OnlineSalesKey ocupa 30,68% do banco de dados (%DB). Ela é uma chave primária da nossa tabela fato e como não precisamos dessa coluna no nosso modelo, podemos excluí-la sem medo!
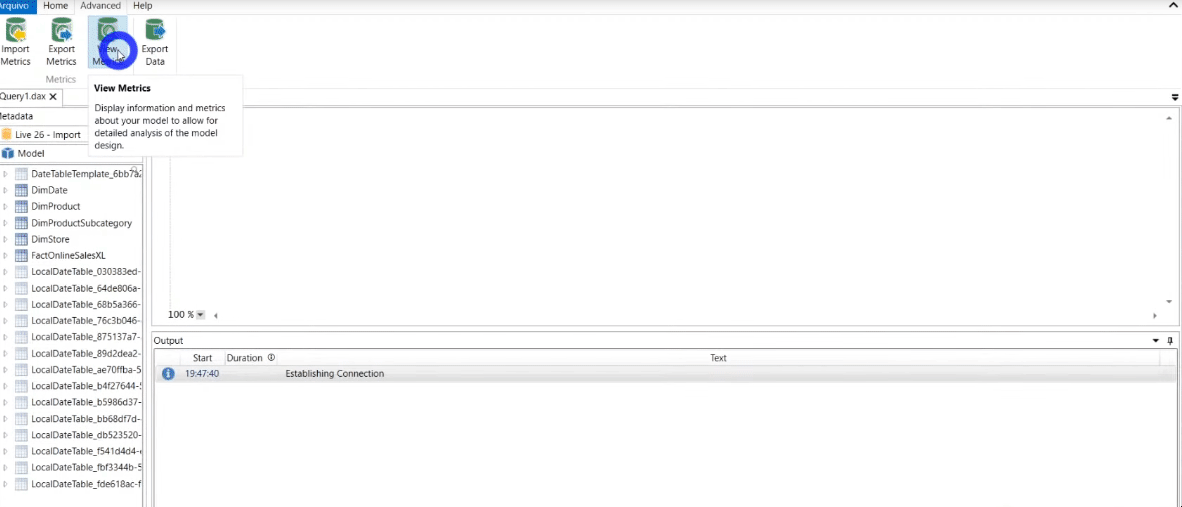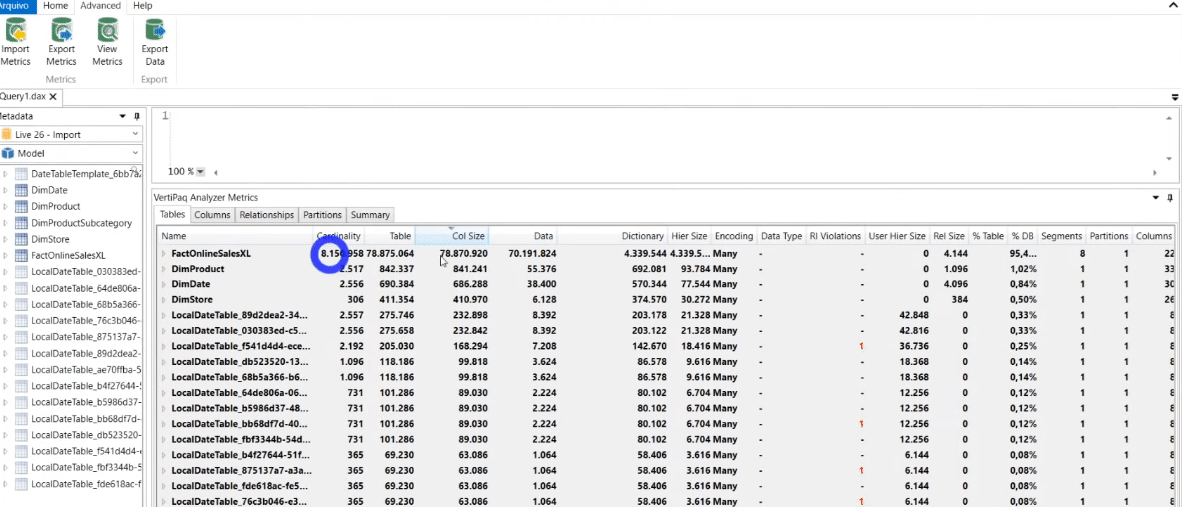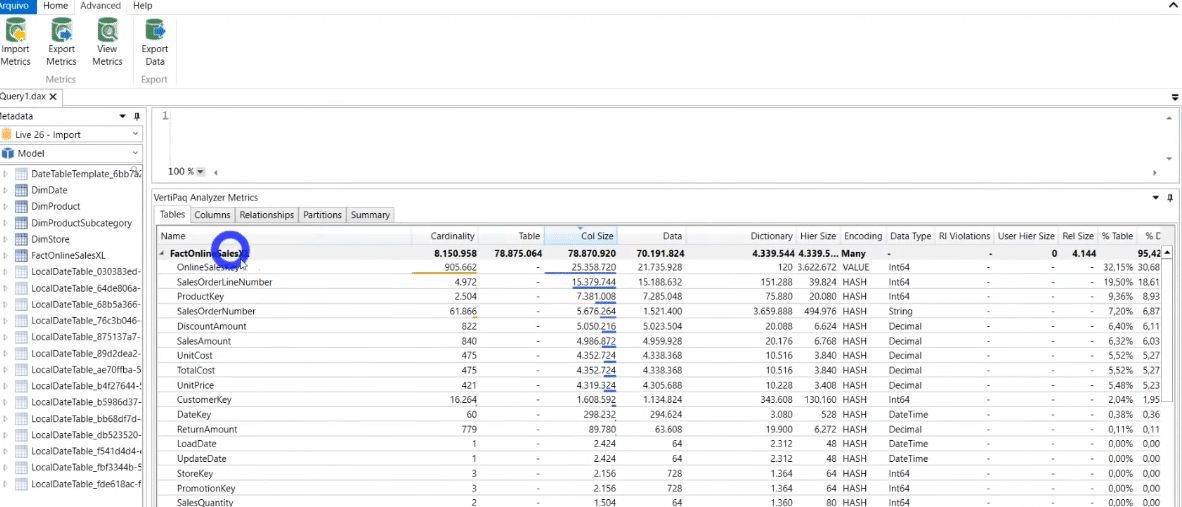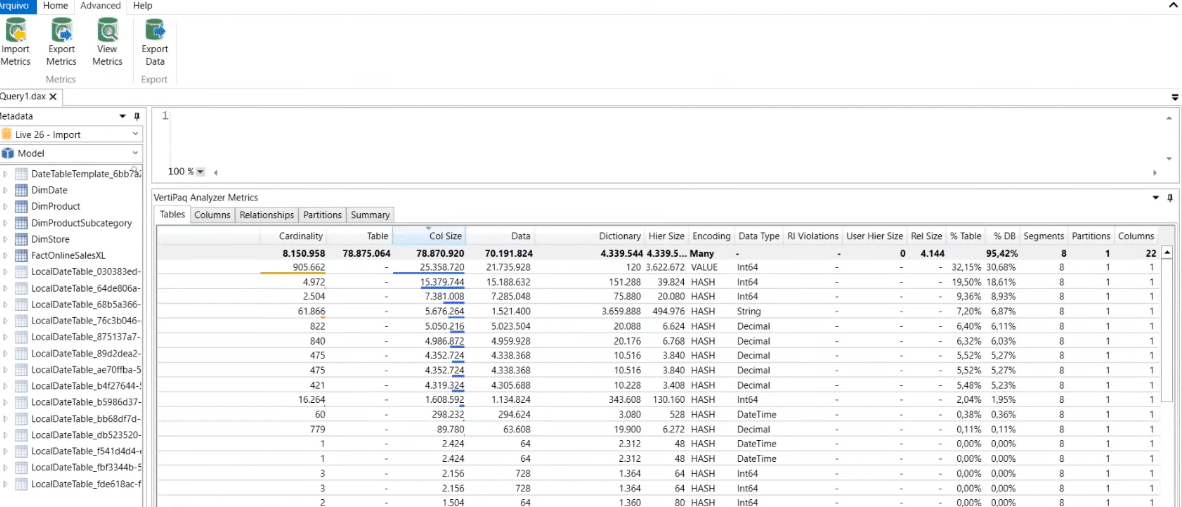
Ah, também vamos excluir a coluna SalesOrderLineNumber. Quando salvarmos esse arquivo .pbix veremos que ele foi de 31 MB para 6 MB! No Power BI o comportamento será o mesmo: redução do tamanho!
Dica:
Você nunca deve levar a chave primária de tabela fato para o PBI! Se quiser fazer uma contagem de linhas você pode usar medidas (não precisa de uma coluna numerando as linhas da tabela fato)!
Após a exclusão dessas duas colunas, se você clicar em ViewMetrics novamente aquela tabela se atualizará. Agora, a maior coluna do nosso modelo é a ProductKey. Mas essa não poderemos excluir porque precisamos dela no relacionamento entre a tabela fato e a tabela dimensão, beleza?!
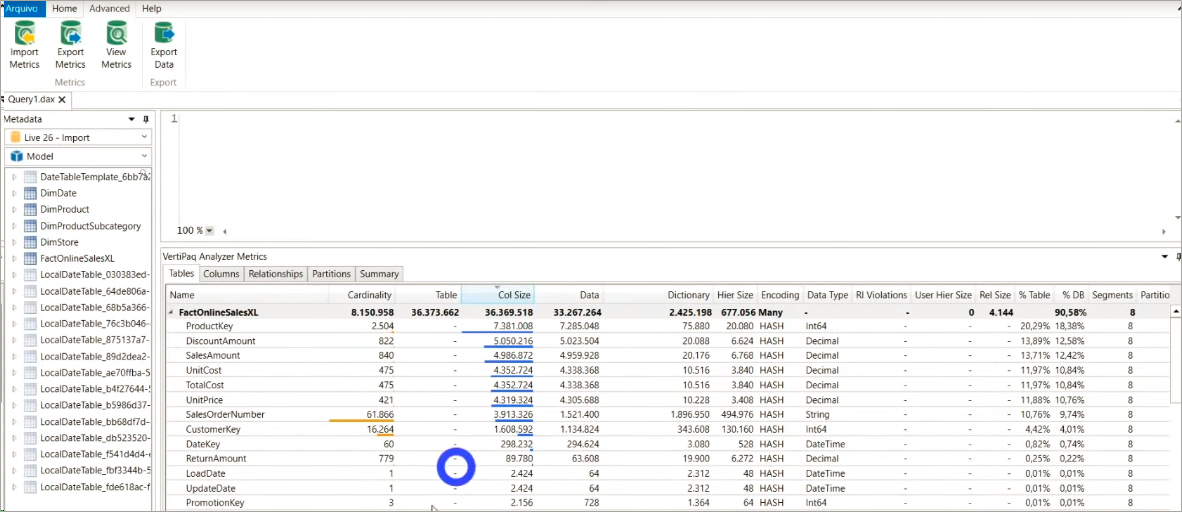
Depois de fazer tudo isso pode ser que seu modelo ainda esteja lento.
– E agora, Leo?!

Agregações em modelos compostos
Essa funcionalidade está disponível para quem tem PRO (não exige capacidade Premium).
Antes, para saber se essa solução se aplica a você responda a seguinte pergunta:
Você realmente precisa analisar tudo a nível de SKU, por CNPJ do cliente, por Dia, etc?
Prossiga se a sua resposta for “não”. Se respondeu “sim”, dê uma olhada nessa solução mesmo assim para já ter em mente como trabalhar com agregações no PBI quando precisar!
Nosso objetivo será resumir as tabelas fato (por categoria de produto, ou segmento de cliente, por exemplo). Fazendo isso estaremos reduzindo o volume de dados e consequentemente teremos um ganho de performance considerável nas consultas.
As principais formas de criar tabelas agregadas são:
- Diretamente no Power Query
- Utilizando uma query no PBI
- Trazendo uma view agregada
- Trazendo uma tabela agregada
Criaremos um modelo composto trazendo a Tabela Agregada usando Import e a Tabela Detalhada usando DirectQuery e por fim, configuraremos as Agregações no Power BI Desktop!
Agregações diretamente no Power Query
Para começar a criação de um modelo composto que faz uso de Agregações, traga tudo primeiro em DirectQuery.
Neste exemplo trabalharemos em cima do mesmo arquivo usado para mostrar o modo de conexão via DirectQuery. No Power Query duplicaremos a consulta FactOnlineSalesXL e a renomearemos para FactAgrPQ, ok?! Essa será nossa tabela agregada!
Para transformá-la numa tabela agregada basta ir em Agrupar por e definir como você deseja agrupar as colunas:
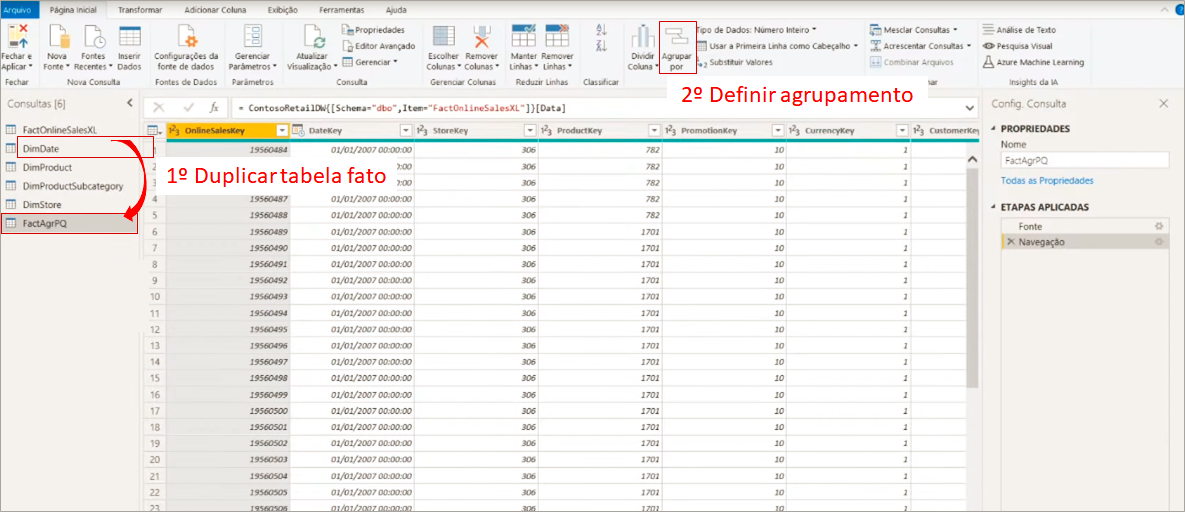
Nesse nosso exemplo a tabela FactOnlineSalesXL não tem a subcategoria do produto então teríamos que antes fazer um merge com a tabela de produto antes de criar essa tabela agregada para poder agrupar por Subcategoria de produto. Então, vamos para uma outra possibilidade: usando view agregada no banco SQL.
View Agregada
Para utilizar essa opção, você deve criar uma view agregada no Microsoft SQL Server Management Studio. Veja a redução no volume de dados que será aplicada quando agruparmos por subcategoria de produtos:
A view criada se chamará vw_FactOnlineSalesAggs, veja:
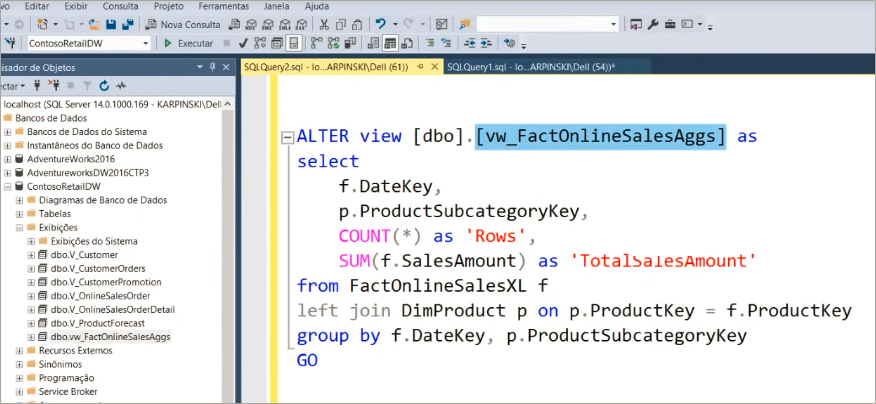
Agora basta conectarmos essa view lá no PBI Desktop! Para agilizar vamos importar via DirecQuery agora (mas no final mudaremos o modo de armazenamento para Import, ok?!).
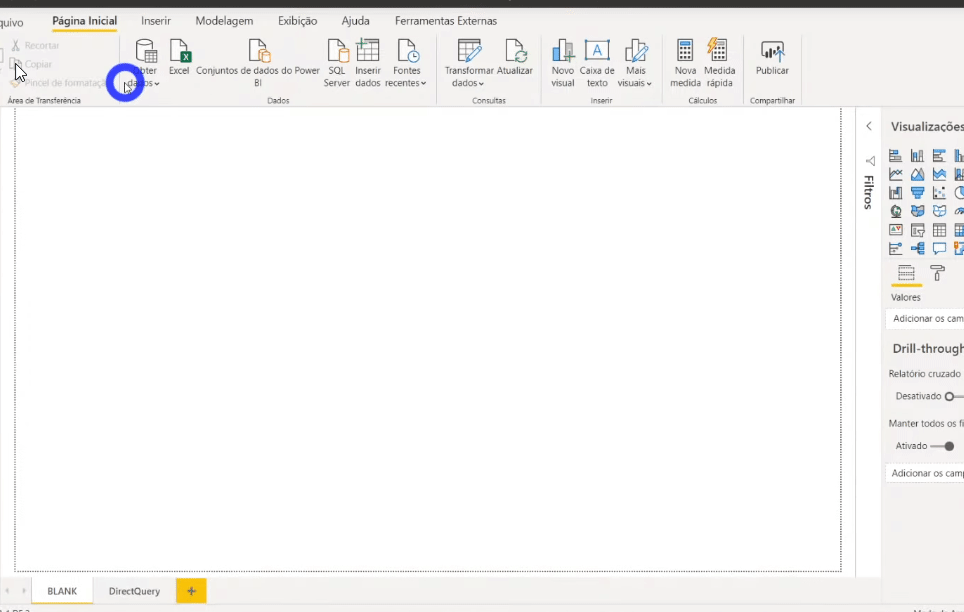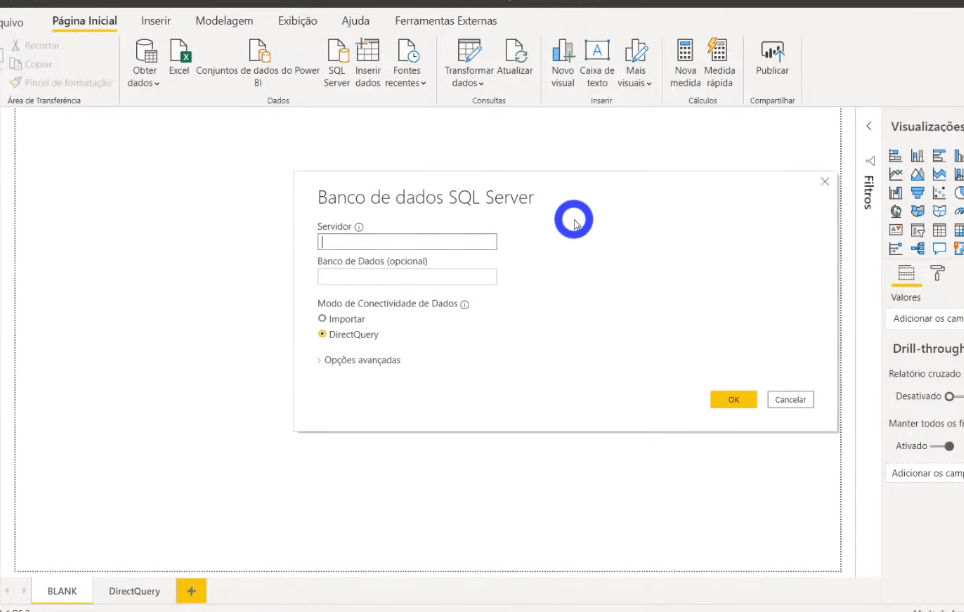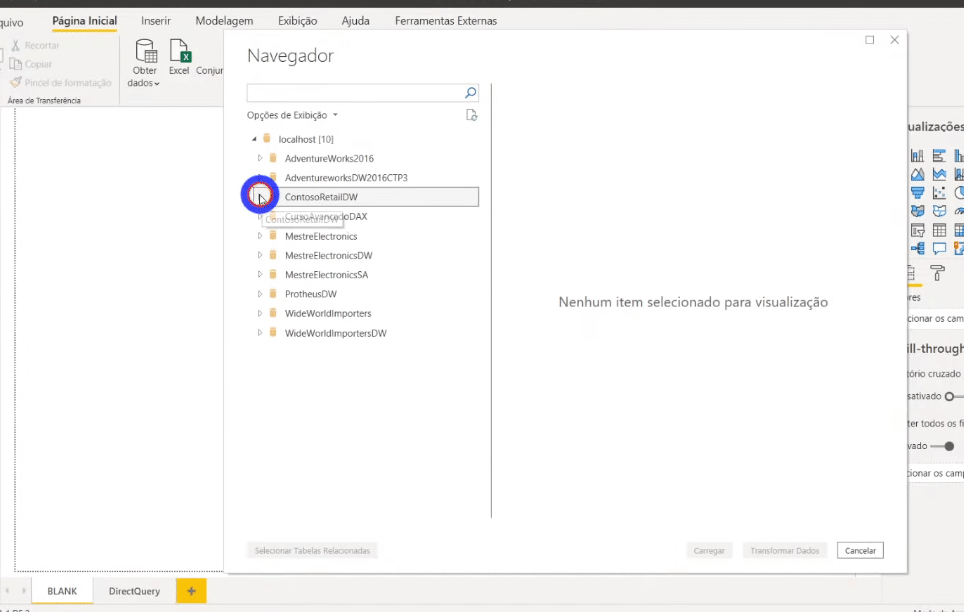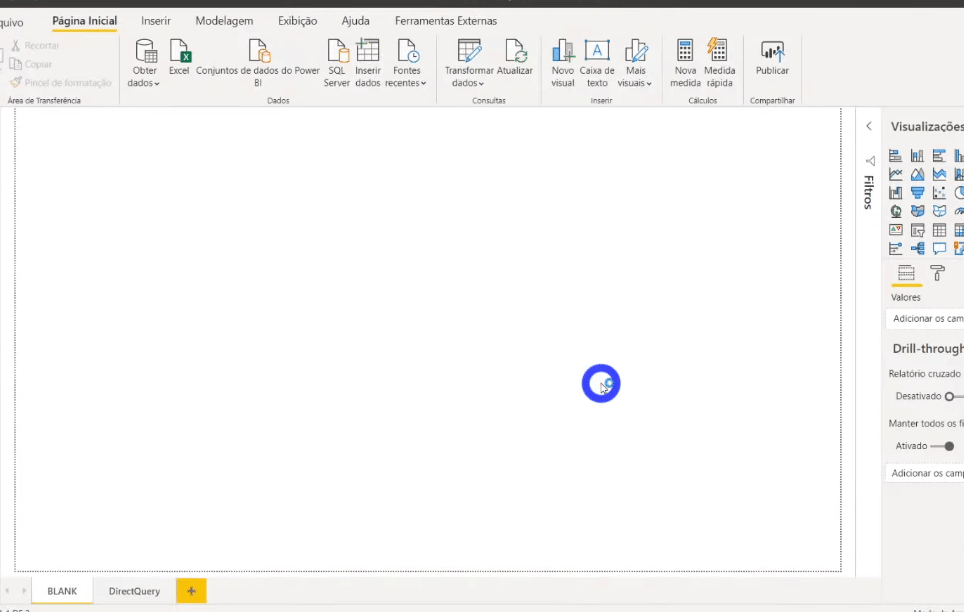
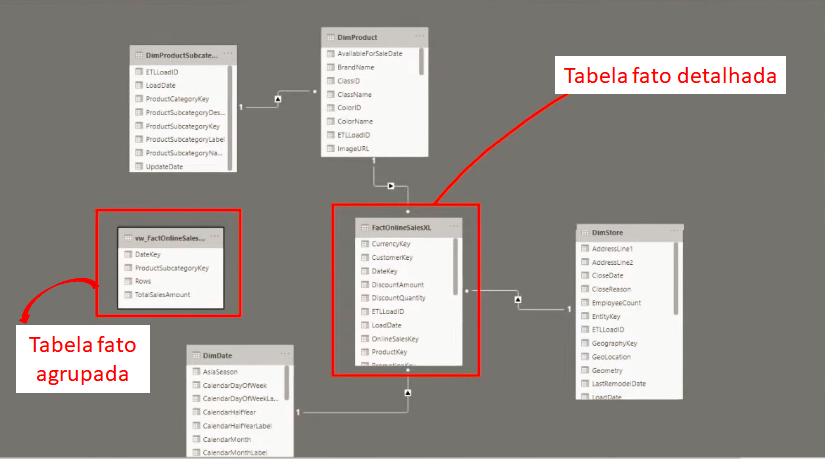
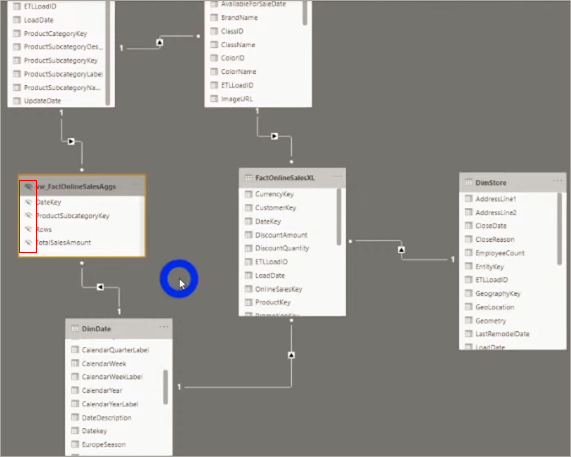
Então, só relembrando: a tabela FactOnlineSalesXL é a tabela fato “original” (completa) e a tabela vw_FactOnlineSalesAggs é a nossa tabela agrupada (apenas 35 mil linhas).
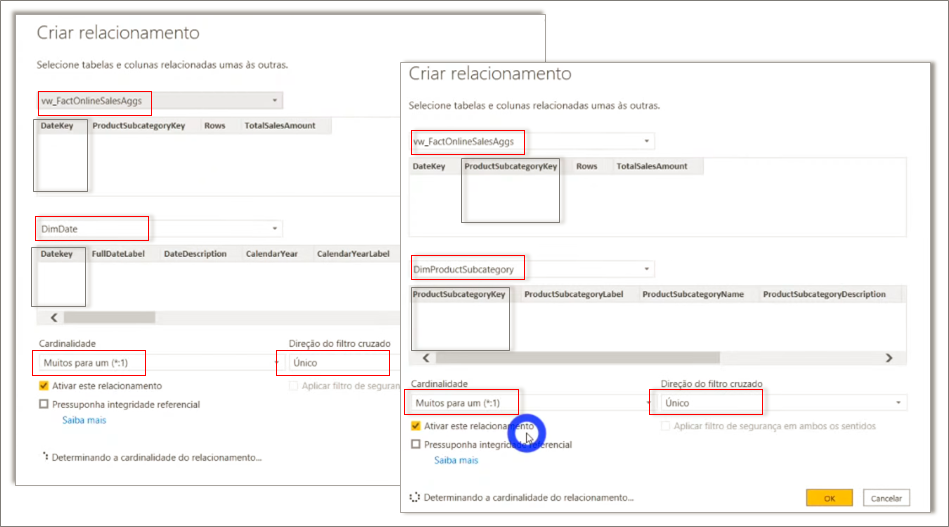
Precisamos relacionar as tabelas novas com as já existentes no modelo, veja:
Você perceberá que agora teremos o modelo Snow Flake – é a forma mais prática de relacionarmos nossa tabela agrupada no modelo.
Agora vem o pulo do gato! Lembra quando disse que estávamos nos conectando na tabela agregada via DirectQuery apenas para agilizar (ser mais rápido) e que depois mudaríamos para o modo Import? É o que vamos fazer a seguir:
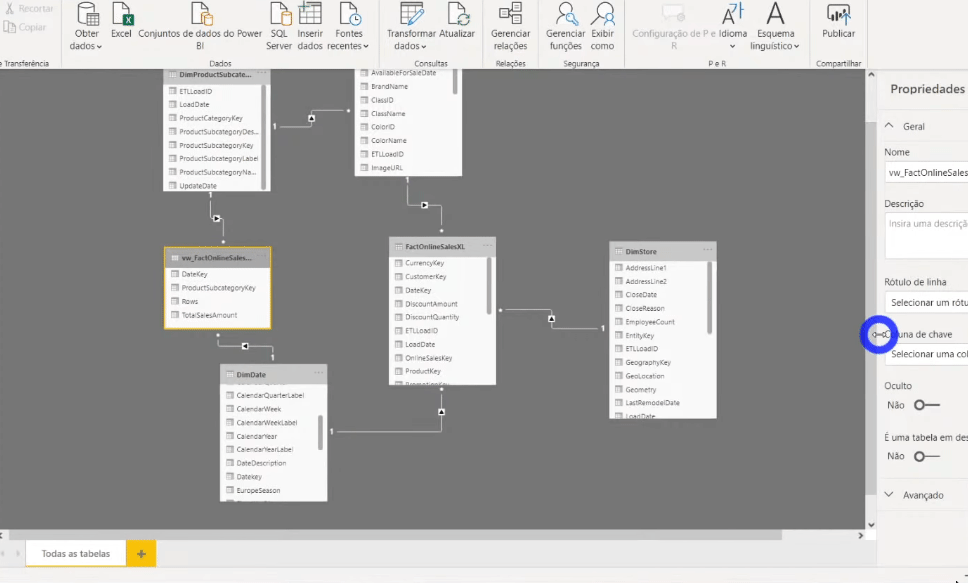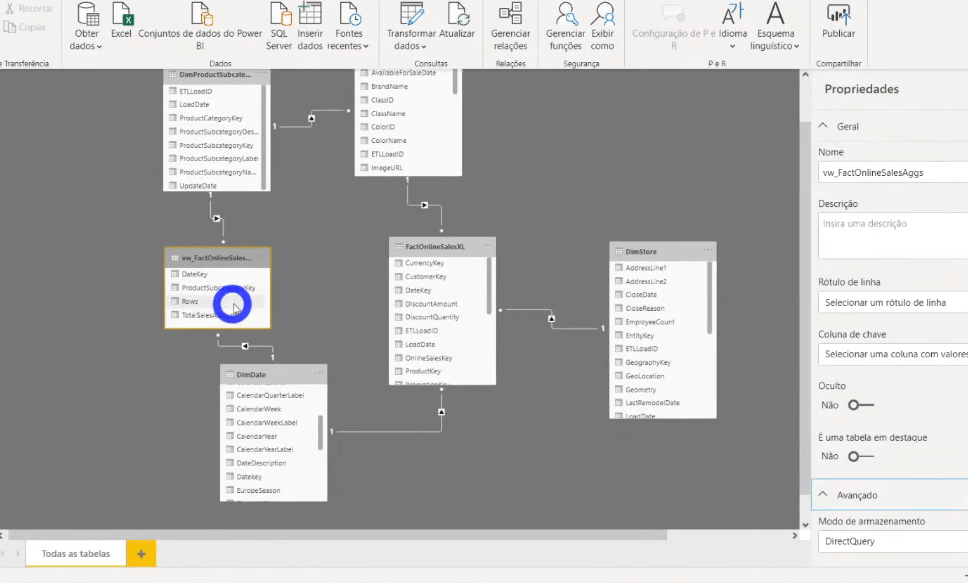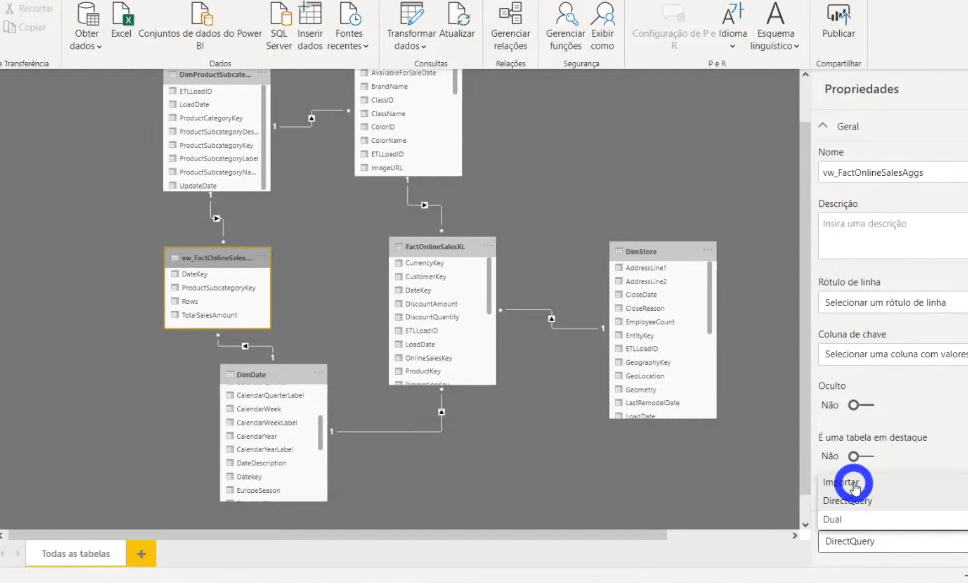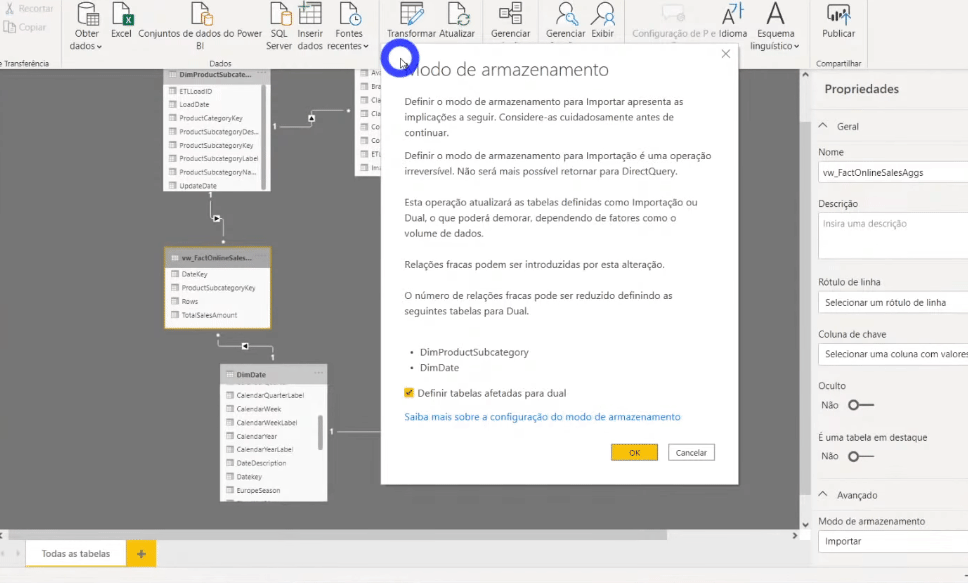
Quando você alterar o modo de armazenamento para Import, aparecerá uma mensagem sugerindo definir as tabelas DimProductSubCategory e DimDate para o modo Dual.
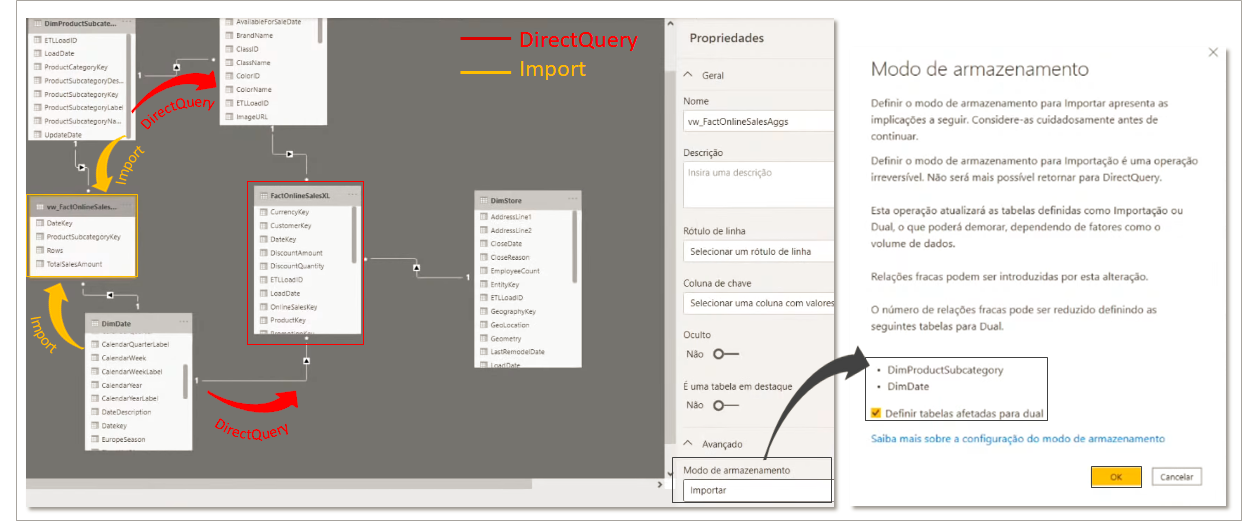
Se analisarmos essas duas tabelas vemos que numa direção estamos indo de encontro a uma tabela armazenada via DirectQuery e na direção oposta via Import. Ao clicarmos em Ok nessa mensagem, definiremos essas tabelas dimensão como Dual para reduzir o número de relações fracas no conjunto de dados e aprimorar o desempenho.
Gerenciando agregações
Agora precisaremos configurar as agregações para que o usuário não tenha que escolher qual tabela usar para ver a informação agregada ou detalhada. Iremos basicamente fazer o mesmo que fizemos no SQL. Agora será o PBI que irá automaticamente fazer essa escolha de acordo com a configuração que definirmos. Para isso basta clicar com o botão direito na tabela fato agrupada (vw_FactOnlineSalesAggs) e depois em Gerenciar agregações. Veja a configuração final:
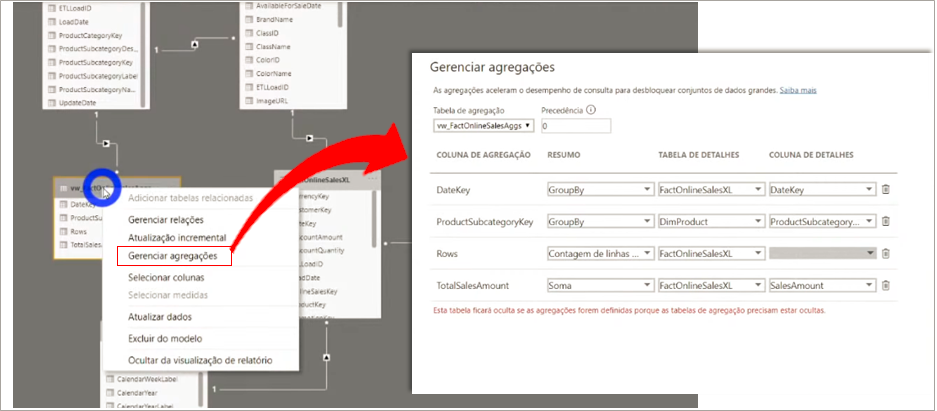
Repare que o PBI automaticamente irá ocultar essa tabela agrupada, afinal já sabemos quando usá-la de acordo com as regras que colocamos, certo?! O usuário não precisa saber que ela existe!
Observe os tamanhos dos arquivos .pbix lado a lado:
Performance usando modelo composto
Vamos também utilizar o Perfomance Analyzer, da mesma forma que fizemos com os arquivos anteriores para verificar o tempo de processamento.
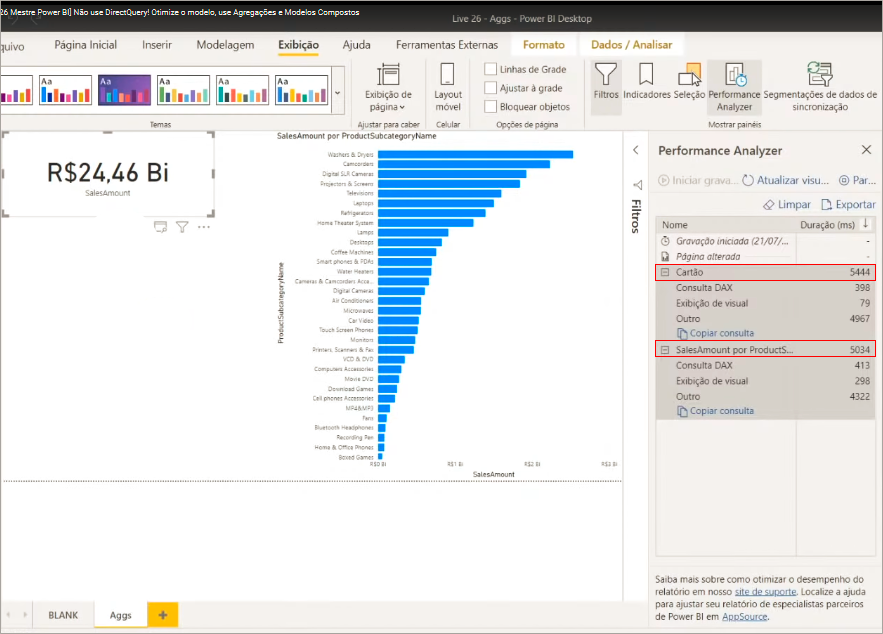
Ah, importante mencionar uma coisa: sempre que fizer uma medida utilize a tabela fato detalhada. Nunca use a tabela agregada para criar medidas DAX, ok?!
Se você tiver curiosidade de ver o que está acontecendo por trás de cada processo desse painel do Performance Analyzer, clique em Copiar consulta para ver a query que o Power Bi faz e cole em algum editor de texto. Veja um exemplo de quando mostramos o dado de uma tabela que está em modo Import num cartão:
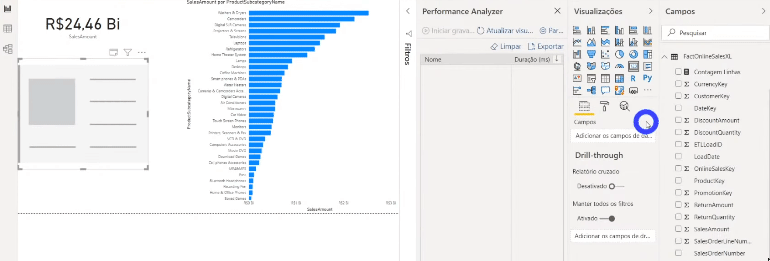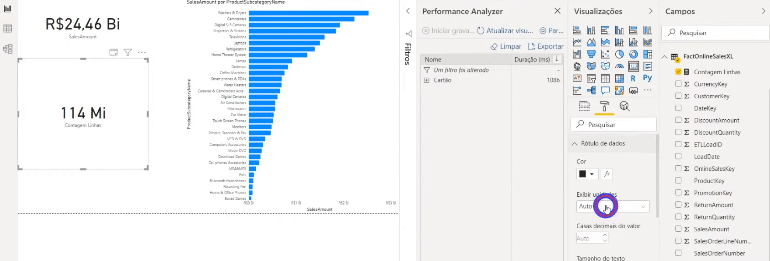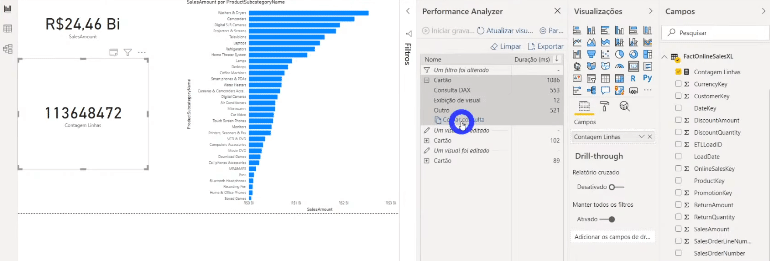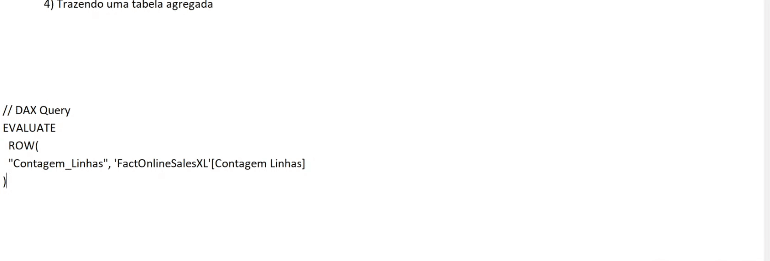
Agora veja um exemplo usando um dado de uma tabela que não foi agregada (modo DirectQuery):
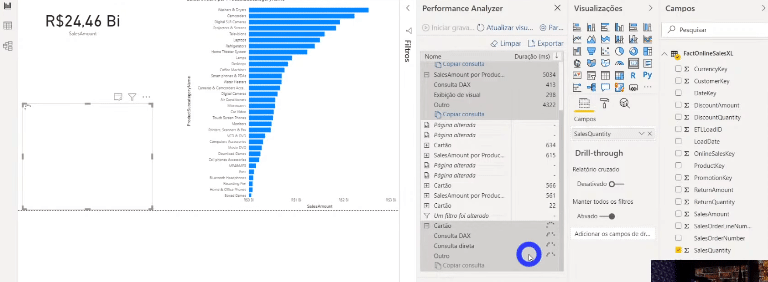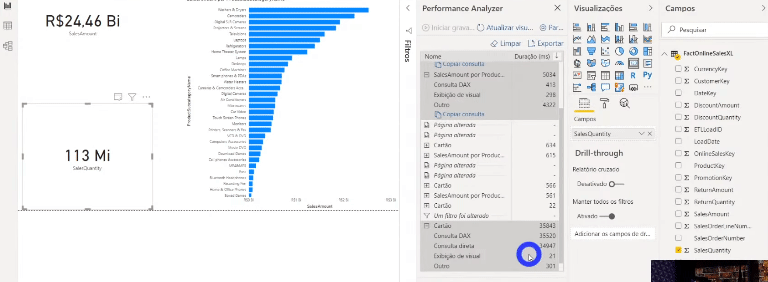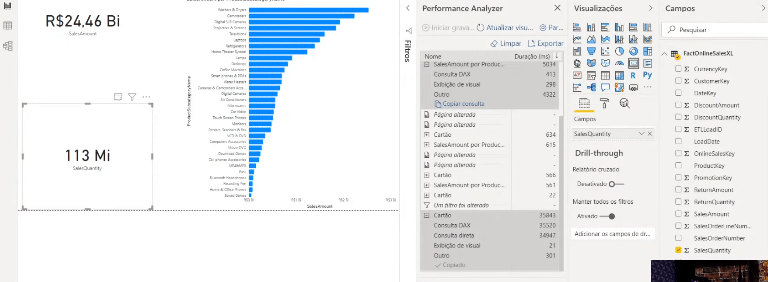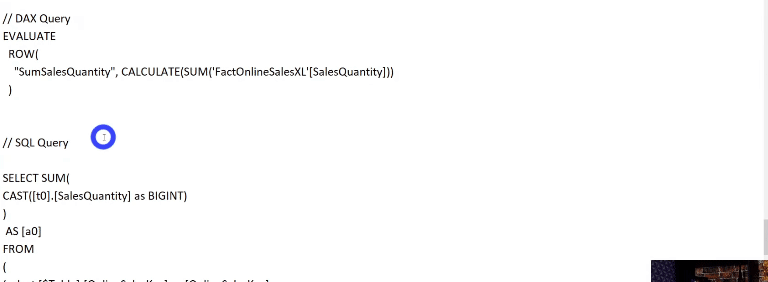
Perceba a diferença entre as querys. Veja quantas etapas a query SQL possui – isso ocorre porque os dados não estão cacheados na memória, lembra?!
Trabalhando com dados em tempo real
Particularmente não costumo trabalhar com esse tipo de modelo (e nem gosto) mas como prometido vou mostrar como eu faria para trabalhar com dados em ‘tempo real’.
Nosso histórico será fixo e traremos apenas dados do último mês (ou últimos dois meses) através do DirecQuery. O restante (histórico) traremos utilizando o modo Import. Na prática importaremos a mesma tabela fato (uma utilizando modo Import e a outra utilizando o modo DirectQuery) e aplicaremos diferentes filtros em cada uma, veja:

Relacione as tabelas fato normalmente (mesmos relacionamentos):
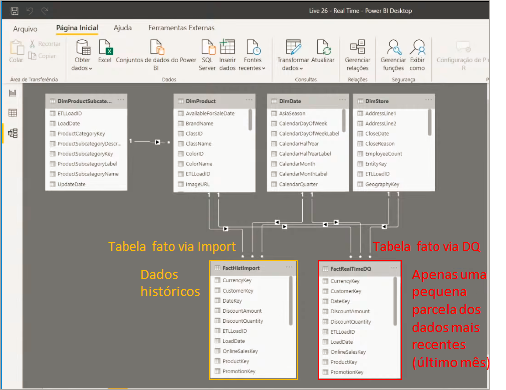
Para ter um visual com informação de ambas as tabelas basta criarmos medidas que somem os valores de cada uma para obter, por exemplo, o total de vendas do passado até hoje.
Durante a Live #26 um participante perguntou:
Leo, teria como colocar parâmetros para a tabela com DQ ficar no mesmo eixo do tempo da Import?
Leonardo Brito
Sim! Na tabela que está em DirectQuery, aplique um filtro no Power Query (ou na query) para trazer apenas o dia anterior para trás.
Se você chegou até aqui: parabéns! O conteúdo além de extenso teve um caráter mais técnico. A seguir algumas vamos consolidar as conclusões mais importantes para finalizarmos com chave de ouro!
Conclusões
- Não usar tudo em DirectQuery, pois é lento;
- Focar sempre em performance no modelo de dados, antes de pensar em deixar o desenvolvimento leve;
- Para deixar o desenvolvimento leve, você deve filtrar os dados e trabalhar com uma fatia apenas;
- Use atualizações incrementais para deixar as atualizações rápidas;
- Para deixar o modelo mais performático, leve o mínimo de colunas e tabelas;
- Se mesmo assim não for suficiente, use Agregações com modelos compostos (Tabela agregada no modelo Import + Tabela detalhada no modelo DirectQuery);
- Para trabalhar com dados em tempo real, aplique um filtro para restringir a quantidade de linhas em DirectQuery. O restante (passado) você deve trazer no modo Import.
Veja também o resumo dos testes que fizemos:

Links úteis
Recomendação da Microsoft sobre a preferência pelo uso do modo Import: https://docs.microsoft.com/pt-br/power-bi/connect-data/desktop-directquery-about
Download do DAX Studio: https://daxstudio.org/
Modos de armazenamento: https://docs.microsoft.com/pt-br/power-bi/transform-model/desktop-storage-mode
Chegamos ao fim de mais um artigo! Espero que tenham curtido! Até a próxima!
Abraços,
Leonardo.


