
Fala, pessoal! Tudo bem?!
Já pensou em usar a combinação Python + Power Bi em seus projetos? Tem interesse em fazer previsões futuras de vendas ou criar visuais customizados com scripts Python? Mario Filho nos ajudará nessas tarefas e dará dicas bem bacanas! Ele é cientista de dados e especialista em Machine Learning – e inclusive já foi premiado em várias competições internacionais desse tema.
O conteúdo de hoje foi baseado na Live #15 Mestre Power BI, beleza?!
Dica:
No site do Mario Filho você vai encontrar links para suas aulas, ebook, podcasts, cursos e muito mais! Clique aqui para acessar: https://www.mariofilho.com/
Afinal, o que é Python?
Assim como Java, C, R, o Python é uma linguagem de programação de “propósito geral” – você pode fazer quase qualquer coisa com ele.
A diferença entre o Python e R é que, como o Python tem uma sintaxe muito fácil e simples de escrever, ele acabou sendo adotado pela comunidade de Data Science, Machine Learing – comunidade científica de modo geral. E com isso, várias bibliotecas de ML foram desenvolvidas para Data Science e por isso acabou substituindo o R em muitos casos.
Como o Python tem uma sintaxe muito fácil e simples de escrever, ele acabou sendo adotado pela comunidade de Data Science, Machine Learing – comunidade científica de modo geral. E em muitos casos acabou substituindo o R.
Mario Filho
Por que você escolheu Python e não R e por que Python é melhor que R?

Hora da treta! Não tem isso de Python ser melhor que R ! Temos que deixar claro aqui que R é uma linguagem estatística. Tudo de mais exótico de estatística você vai encontrar em R! E definitivamente pra essa finalidade, R acaba sendo melhor que Python.
Mas quando você pensa num projeto como um todo e nas integrações que temos que ter com outros softwares ou linguagens é muito mais fácil você realizar isso com Python. Ele funciona como ponte entre algumas linguagens, por exemplo: é possível você chamar um código em C dentro do seu código em Python e mesmo assim ter uma boa performance.
Então por essa simplicidade de sintaxe e facilidade de integração com outras linguagens e softwares, Python tem ganhado cada vez mais destaque na comunidade.
Clique Aqui para aprimorar suas habilidades na resolução de problemas complexos.
Como e onde posso usar Python no Power Bi?
Algumas possibilidade de uso do Python no Power Bi que identificamos foram essas:
- Para importar fontes de dados que não estão disponíveis ou não performam tão bem no PBI (web scrapping, bases não relacionais, etc);
- Para aplicar transformações de dados do Power Query
- Para incorporar Machine Learning na sua base
- Para criar elementos visuais customizados com bibliotecas Python
Abordaremos em detalhes os itens 3 e 4, que são as aplicações mais usadas! Vamos passar o passo a passo para você realizar a integração PBI + Python. Preparados?! Vamos lá!
Passo a Passo para usar Python
Precisamos instalar o Python! Segue o passo a passo:
1. Baixar o arquivo Python 3.7 através do site e realizar a instalação
O arquivo executável para fazer o download encontra-se aqui: https://www.python.org/downloads/release/python-374/
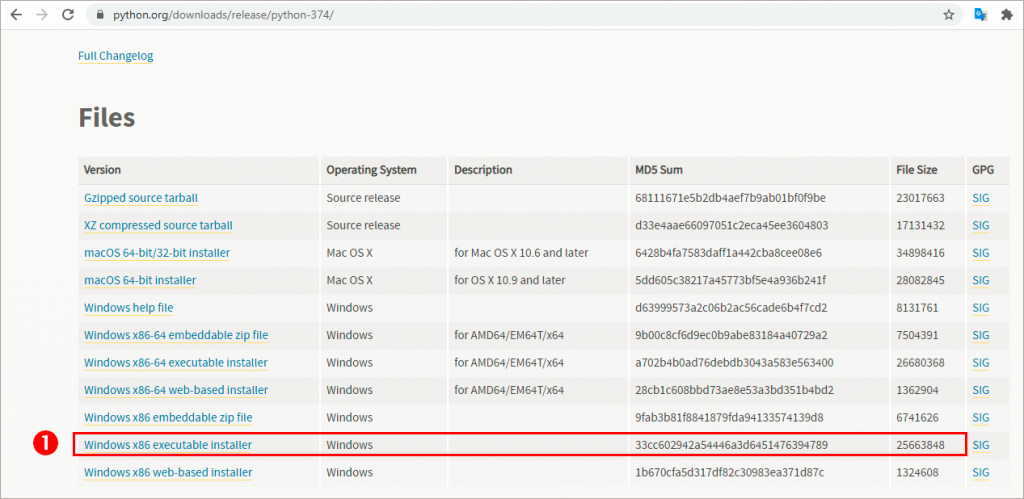
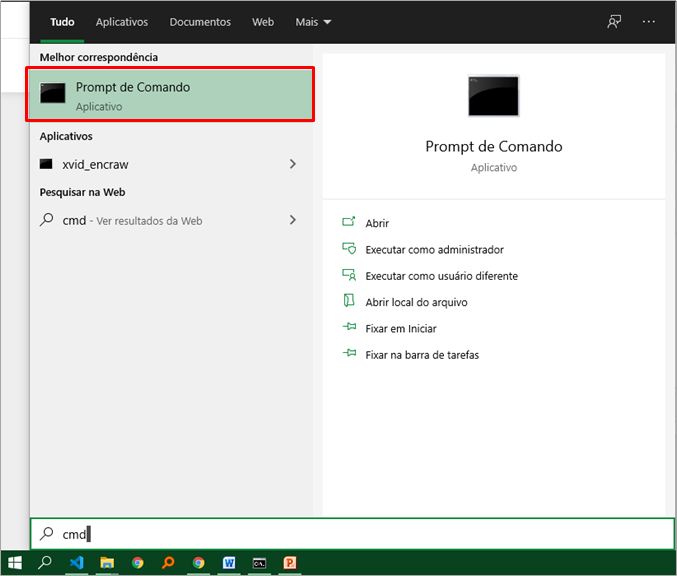
2. Abrir CMD (prompt de comando):
Basta digitar “cmd” na busca do Windows que já vai aparecer:
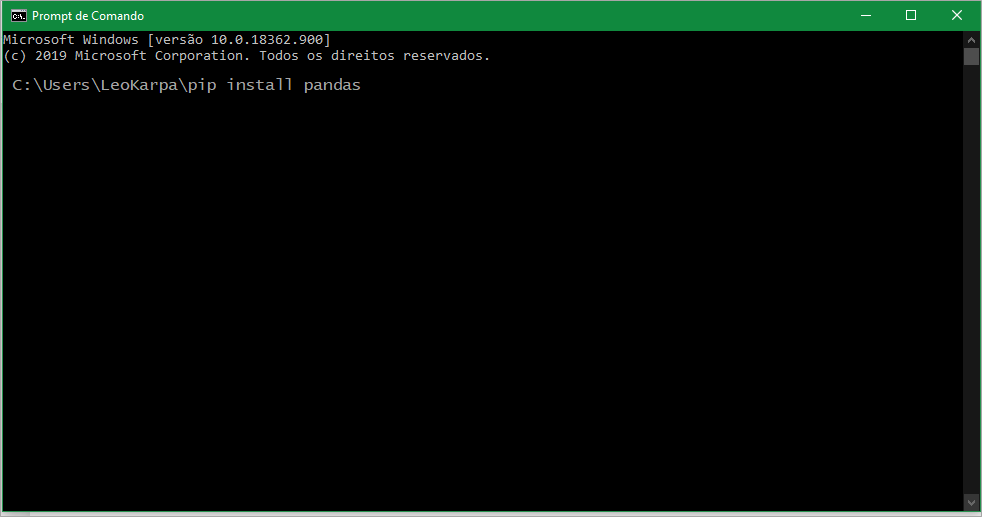
3. Instalar as seguintes bibliotecas digitando na janela do CMD:
pip install pandas
pip install xlrd
pip install matplotlib
pip install scikit-learn
pip instal plotnine
pip install seaborn
pip install notebook
Digite cada linha acima uma de cada vez. Após digitar a primeira linha, dê enter. Espere a instalação concluir e siga para a próxima.
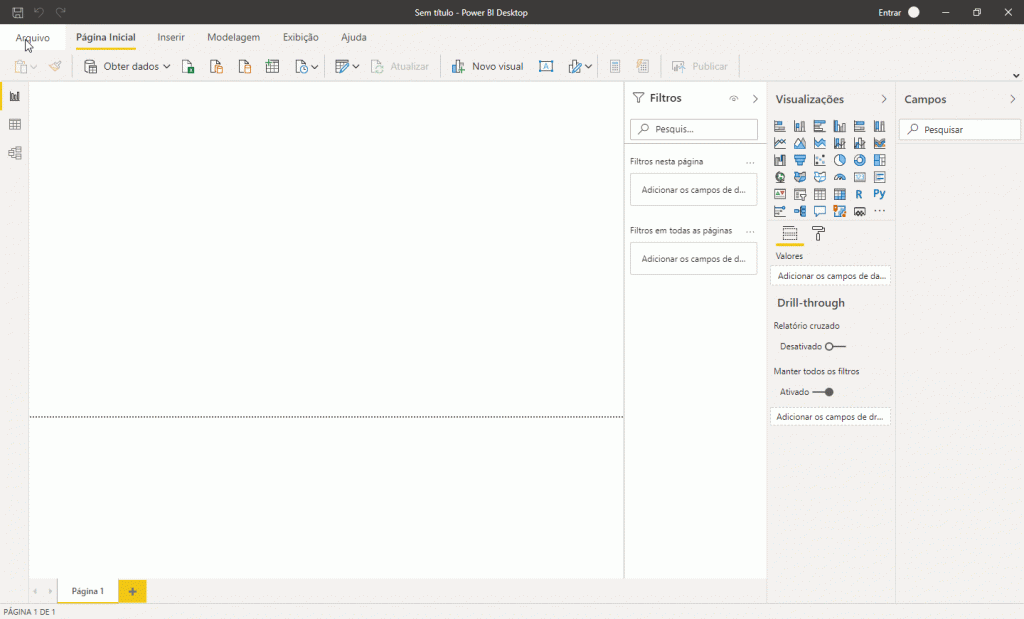
4. Desativar a opção “Armazenar os conjuntos de dados usando o formato de metadados aprimorado” em Recursos de visualização no Power Bi Desktop. Veja:
5. Caso o Power Bi não identifique automaticamente o diretório do Python, você deve adicionar o diretório manualmente:
Etapas: Arquivo → Opções e configurações → Scripts do Python → Diretórios base do Python detectados:

Desafio 1: Previsão de Vendas
Base de dados
Nosso cenário conta com a seguinte base de dados: um arquivo em Excel com colunas de Data da Emissão da Nf, NFE, Código do produto, Quantidade de itens vendidos, Valor unitário de cada produto e Valor da venda. Veja:
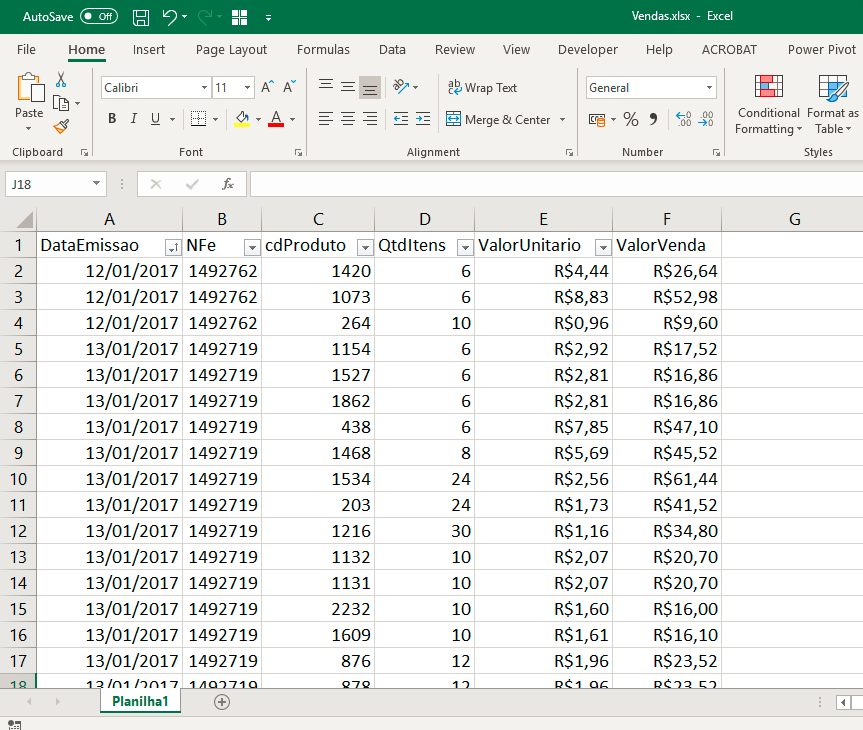
Escrevendo em Python
Nessa seção iremos mostrar linha a linha do código e descrever o que foi realizado em cada uma delas. No final disponibilizarei o código completo (para copiar e colar), ok?!
O Mario, durante a live utilizou o Jupyter lab para rodar linha a linha os comandos em Python. Replicaremos a mesma coisa usando o Jupyter notebook, beleza? Na prática, vai ser a mesma coisa! Não se preocupe em instalar o Jupyter Notebook no seu computador agora, o objetivo neste momento é entender o que cada linha de código fará com nossos dados.
Uma coisa importante, o arquivo Vendas.xlsx precisa estar no mesmo diretório do Jupyter Notebook caso você teste o código por lá, ok?!
Primeiro iniciaremos com o comando de importação da biblioteca que vamos utilizar:
Comando Python:
import pandas as pd
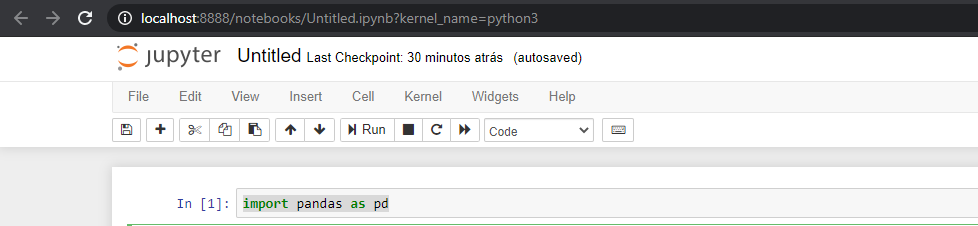
Basta digitar o comando acima na primeira célula e clicar em Run.
Veja que quando utilizamos esse as “pd” é como se estivéssemos dando um apelido para nossa biblioteca (geralmente são palavras pequenas que representem a biblioteca que vamos utilizar nos comandos a seguir). Você notará na próxima linha que usaremos esse “pd” que definimos para indicar de que biblioteca estamos utilizando determinada função.
Ah, essa linha não tem outputs então poderemos seguir para o próximo comando.
Comando Python:
dados = pd.read_excel("Vendas.xlsx", parse_dates=['DataEmissao'])
Esse comando também não tem outputs. Ele serve apenas para carregar os dados – aquele arquivo Excel (nossa base de dados).
Uma dica bacana é sempre colocar o argumento parse_dates (mesmo que ele não seja obrigatório) pois, nem sempre Python reconhecerá sua coluna de Datas automaticamente, beleza?!
Dica:
Indique para o Python qual é a coluna de Data do seu arquivo utilizando parse_dates como argumento da função read_excel ou read_csv (caso seu arquivo seja .csv) ao utilizar o Pandas.
Próxima linha! Digite o comando abaixo:
Comando Python:
dados.head()
Se você deixar o argumento vazio como está no código acima, conseguiremos ver as 5 primeiras linhas dos nossos dados carregados. Mas você pode mudar para 10, 15, 100 caso queira ver mais linhas, ok?! Esse comando gera um output, veja:
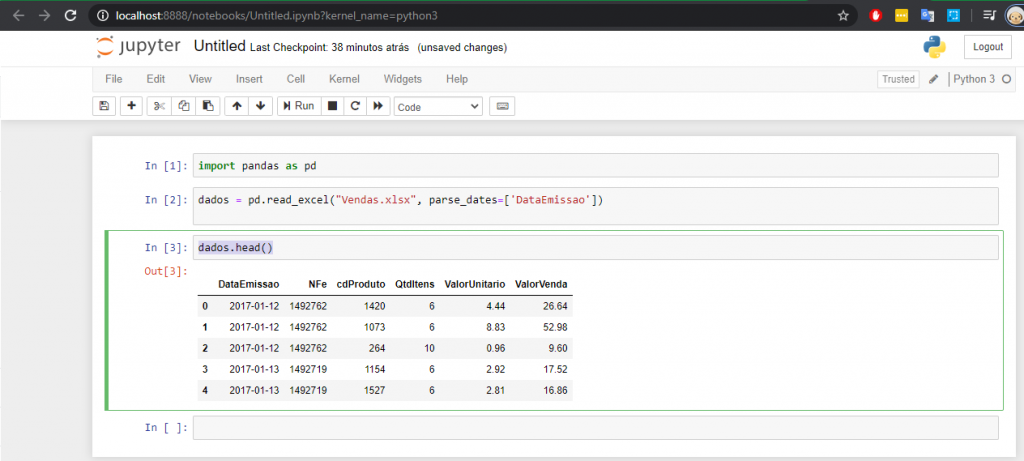
Bom, nosso objetivo será fazer uma previsão diária de vendas mas sabemos que há mais de uma nota fiscal emitida por dia, certo?! Tendo isso em mente, precisaremos agrupar os nossos dados por produto e data (colunas cdProduto e DataEmissao). Com isso teremos um registro para cada data e cada produto, ok?!
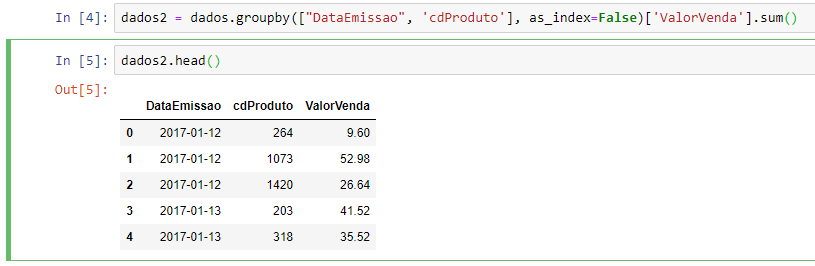
Comando Python:
dados2 = dados.groupby(["DataEmissao", 'cdProduto'], as_index=False)['ValorVenda'].sum()
Veja que o nome do dataframe (dados2) é diferente do dataframe da nossa base original (dados), ok?! Estamos usando nossa tabela original (dados) e realizando um agrupando com base em duas colunas.
Ao utilizar a função groupby precisamos do nome das colunas que serão únicas, nesse caso são duas: “DataEmissao” e “cdProduto”. Ou seja, esse par de valores serão únicos em cada linha.
Ah, esse argumento as_index=False é importante! Se não colocarmos teremos que trabalhar com índice do pandas e isso vai complicar um pouco nosso modelo.
E a coluna “ValorVenda”? Ela aparecerá agregada (somada) pra cada um dos valores únicos que aparecerem, por isso a função sum( ) nessa coluna.
Visualizando o resultado da linha com dados2.head(), temos o seguinte:
Agora, precisamos separar essa data em alguns componentes e depois removê-la. Veja que os comandos abaixo são bem intuitivos:
Comando Python:
dados2['Dia_do_mes'] = dados2['DataEmissao'].dt.day dados2['Mes'] =dados2['Dia_do_mes'] = dados2['DataEmissao'].dt.day dados2['Mes'] = dados2['DataEmissao'].dt.month dados2['Ano'] = dados2['DataEmissao'].dt.year dados2['Dia_da_semana'] = dados2['DataEmissao'].dt.weekday dados3 = dados2.drop("DataEmissao", axis=1)
Como já mostramos para o Python que a nossa coluna de data é a DataEmissao, será possível encontrar o dia, mês, ano e dia da semana dessa coluna facilmente utilizando as funções acima (dt.month, dt.year, etc). No fim, a função drop vai excluir a coluna “DataEmissao” afinal já temos todos os componentes que precisamos.
Vamos dar uma olhadinha em como ficou? Se digitarmos apenas o nome da do dataframe que criamos (dados3), conseguimos ver o seguinte no Out[7]:
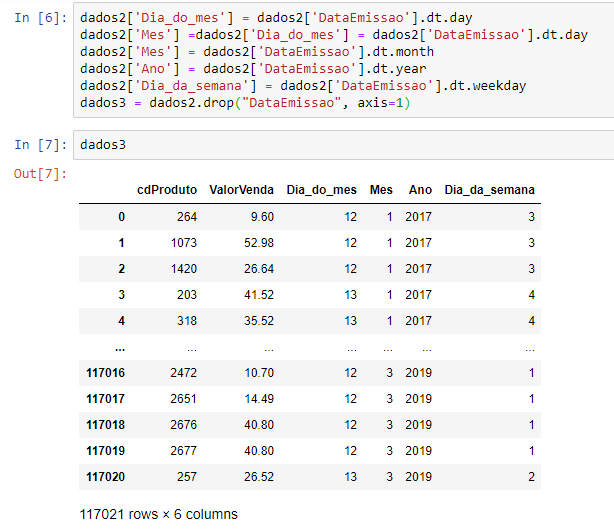
Essa etapa é importante porque vai ajudar nosso modelo a entender a sazonalidade das vendas.
Agora, vamos precisar da biblioteca Scikit-learn. Ela é a biblioteca mais popular de Machine Learning em Python.
Estamos trabalhando com um modelo de Machine Learning que chamamos de supervisionado. Basicamente você usa como input as variáveis de entrada e o alvo (o que você quer prever). E o modelo vai tentar achar padrões que vão relacionar essas variáveis e tentar prever novos alvos. E para fazer isso, utilizaremos uma árvore de decisão.
A primeira coisa que faremos é identificar os dias, meses, dia da semana que são mais preditivos – que se destacam mais. Podemos dar como exemplo o mês de dezembro que, em geral, temos mais vendas de panetones se estivermos falando de uma loja que venda esses tipos de produtos. Ou, se estivermos falando de uma loja de fantasias, fevereiro é o mês que mais se destaca – ou seja, as vendas aumentam nessa época por causa do carnaval, certo?! São essas regrinhas que o modelo vai tentar encontrar na nossa base de dados sempre com o objetivo de prever o valor de vendas futuro.
Comando Python:
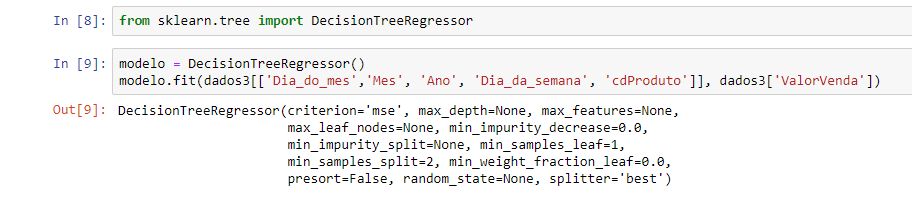
from sklearn.tree import DecisionTreeRegressor modelo = DecisionTreeRegressor() modelo.fit(dados3[['Dia_do_mes','Mes', 'Ano', 'Dia_da_semana', 'cdProduto']], dados3['ValorVenda'])
Após o comando de importação, criamos o objeto chamado modelo e utilizaremos a árvore de decisão para fazer uma regressão por isso o nome DecisionTreeRegressor( ).
Na linha logo abaixo vamos o método fit. É o método para que o modelo possa encontrar/aprender essas regrinhas que mencionamos com base nas colunas informadas. Então esse método vai olhar todos esses dados que inserimos como argumento e buscar a melhor regra que prevê o valor da venda pra cada dia e produto e, por fim, vai armazenar essas regrinhas encontradas. Veja o Out[9] abaixo:
Você deve estar pensando:
– Entendi, Mario! O modelo já aprendeu essas regras e mostrou na tela. E agora, como fazer para o modelo realizar a predição das vendas nas datas futuras?
Primeiro precisaremos usar uma função do Pandas chamada date_range. É através dela que definiremos o intervalo de datas do futuro. A sintaxe é bem simples:
Comando Python:
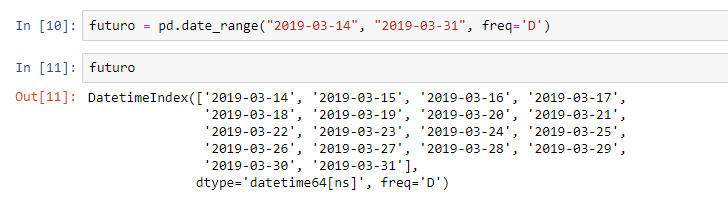
futuro = pd.date_range("2019-03-14", "2019-03-31", freq='D')
Essa função irá criar uma sequência de datas. Terá como primeiro argumento a primeira data igual a 2019-03-14. Definimos essa data porque é aquela subsequente à nossa última data de vendas da nossa base – na figura 9 vemos que a última venda ocorreu dia 2019-03-13. O próximo argumento representa a data final do intervalo. E, como terceiro argumento inserimos freq=’D’ porque queremos uma frequência em dias, ok?!
Ao digitar o nome desse objeto (futuro), veremos o resultado:
Com essas datas criadas, o próximo passo será criar aquelas decomposições da data (semelhante ao que fizemos para DataEmissao: dia, mês, ano, dia da semana) e associar cada linha de data a um código de produto (cdProduto). O código ficou assim:
Comando Python:
futuro_todos = [] for cdProduto in dados3['cdProduto'].unique(): futuro_df = pd.DataFrame() futuro_df['Dia_do_mes'] = futuro.day futuro_df['Mes'] = futuro.month futuro_df['Ano'] = futuro.year futuro_df['Dia_da_semana'] = futuro.weekday futuro_df['cdProduto'] = cdProduto p = modelo.predict(futuro_df) futuro_df['ValorVenda'] = p futuro_todos.append(futuro_df) futuro_todos_df = pd.concat(futuro_todos, ignore_index=True) futuro_todos_df.head()
Observe que a ordem de decomposição da data futura foi a mesma que fizemos para DataEmissao, beleza?!
Veja que usamos também a função predict e é ela a responsável por gerar as previsões de vendas para cada dia futuro (que especificamos naquele intervalo de datas) e para cada produto.
A função append irá salvar todos esses dataframes que criamos na lista futuro_todos. Veja que o criamos uma lista vazia no início do código quando escrevemos a sintaxe futuro_todos = []. Esse append é para adicionar itens nessa lista.
No fim, utilizamos a função concat que vai pegar esses dataframes e juntar numa coisa só. Veja o resultado abaixo:
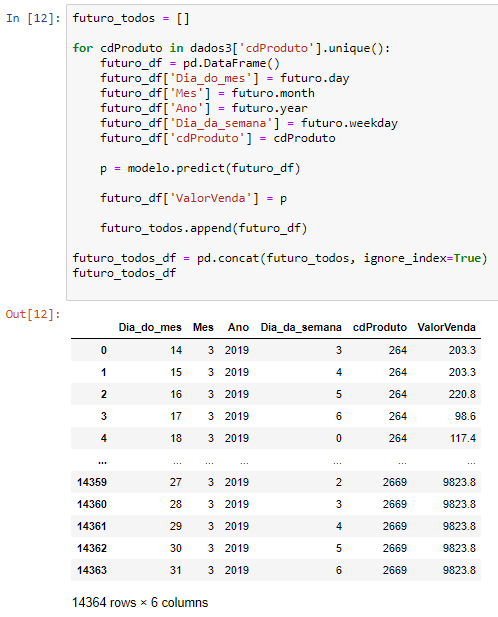
Gostou?! Poucas linhas de código e conseguimos obter valores de previsão de vendas! Passamos bem rápido pelo código mas a ideia é ter um overview do que é possível fazer com Python + Power Bi, ok?! Se precisarem se aprofundar no tema, deem uma olhada no site do Mario Filho porque tem muita coisa bacana lá!
O código completo ficou assim (você precisará dele para a próxima etapa):
import pandas as pd dados = pd.read_excel("Vendas.xlsx", parse_dates=['DataEmissao']) dados2 = dados.groupby(["DataEmissao", 'cdProduto'], as_index=False)['ValorVenda'].sum() dados2.head() dados2['Dia_do_mes'] = dados2['DataEmissao'].dt.day dados2['Mes'] = dados2['DataEmissao'].dt.month dados2['Ano'] = dados2['DataEmissao'].dt.year dados2['Dia_da_semana'] = dados2['DataEmissao'].dt.weekday dados3 = dados2.drop("DataEmissao", axis=1) from sklearn.tree import DecisionTreeRegressor modelo = DecisionTreeRegressor() modelo.fit(dados3[['Dia_do_mes','Mes', 'Ano', 'Dia_da_semana', 'cdProduto']], dados3['ValorVenda']) futuro = pd.date_range("2019-03-14", "2019-03-31", freq='D') futuro_todos = [] for cdProduto in dados3['cdProduto'].unique(): futuro_df = pd.DataFrame() futuro_df['Dia_do_mes'] = futuro.day futuro_df['Mes'] = futuro.month futuro_df['Ano'] = futuro.year futuro_df['Dia_da_semana'] = futuro.weekday futuro_df['cdProduto'] = cdProduto p = modelo.predict(futuro_df) futuro_df['ValorVenda'] = p futuro_todos.append(futuro_df) futuro_todos_df = pd.concat(futuro_todos, ignore_index=True) futuro_todos_df.head()
Seguindo para o Power BI…
Adicionando o script de previsão no Power Bi
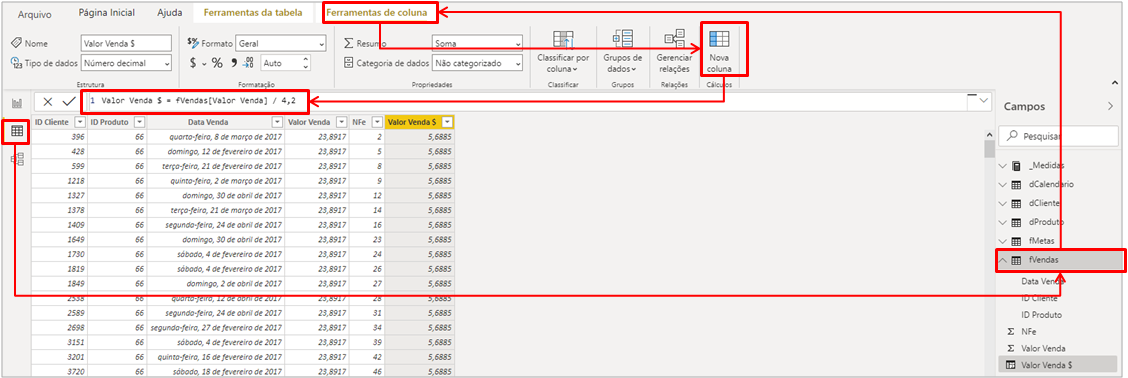
Importe o arquivo Vendas.xlsx para o Power Bi e renomeie o nome da consulta no editor de consultas para fVendas (‘f’ de tabela fato). Duplique essa consulta e renomeie para fPrevisão.
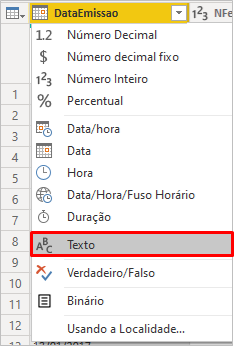
Veja que o Power Bi vai aplicar automaticamente uma etapa de transformação de tipo de dado na coluna DataEmissao, mas não queremos isso porque o formato de data do Python é diferente do formato de data do PBI. Veja a transformação aplicada automaticamente:

Para corrigir, basta mudar o tipo para texto (inserindo uma nova etapa – ou editando a atual):
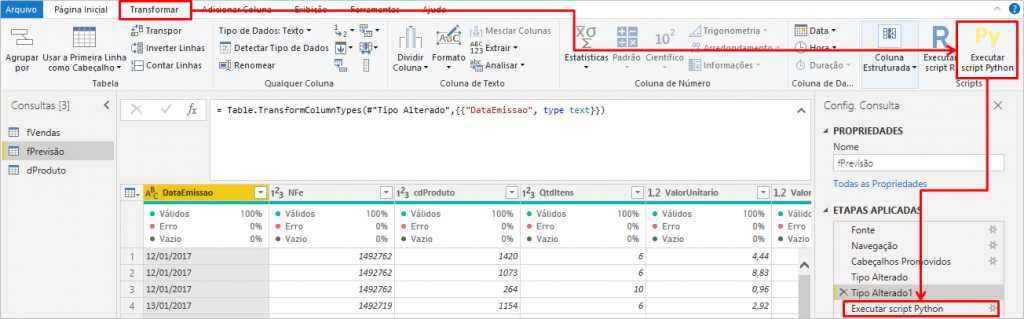
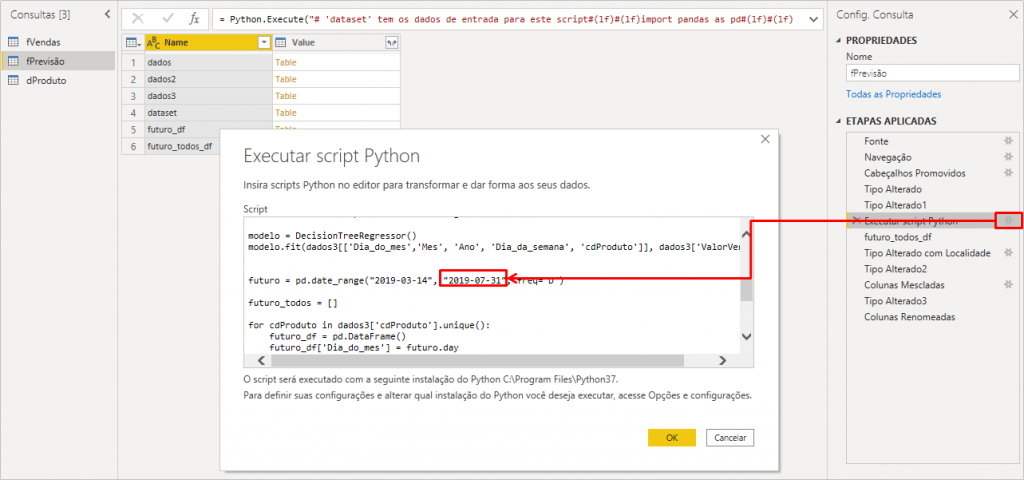
Agora vamos adicionar nosso Script em Python clicando no botão Executar script Python:
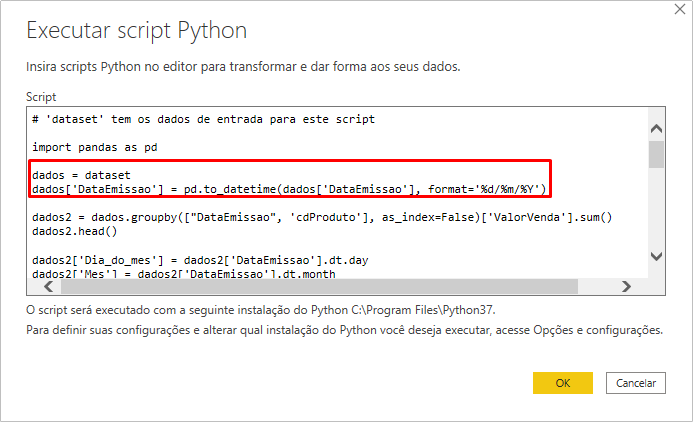
Na próxima janela que aparecerá, insira o código completo que mostramos ali em cima mas substitua essa linha “dados = …” conforme indicado aqui embaixo:
Remover esse trecho do código completo:
dados = pd.read_excel("Vendas.xlsx", parse_dates=['DataEmissao'])
Adicionar esse trecho no lugar do trecho removido:
dados = dataset
dados['DataEmissao'] = pd.to_datetime(dados['DataEmissao'], format='%d/%m/%Y')
Veja como ficou:
Após clicar em OK, demorará um pouco para que o PBI execute o script em Python.
É sempre bom ressaltar que é preferível que você execute o script fora do PBI e jogue o resultado do script para um banco de dados, por exemplo – e assim o time de BI conseguirá conectar diretamente no banco de dados para extrair esses dados. É aquilo né:
Sempre a ferramenta certa para o problema certo!
MARIO FILHO
Nós estamos mostrando algo que é possível de fazer no PBI mas se você tiver uma estrutura por fora para executar esse script e inserir os dados num banco de dados, é melhor, ok?!
Resumindo: o ideal mesmo é que o processamento (criação e treinamento do modelo de ML) ocorra fora do PBI. Não existe ferramenta que vai ser boa em tudo! O Power Bi é excelente para fazer ETL simples, DAX / modelagem de dados, e visuais nem se fala… Mas para criar e treinar modelos de ML bem como fazer ETL’s complexas não! Veja só o tempo que o PBI levou para carregar as tabelas e executar o Script Python!
Não existe ferramenta que vai ser boa em tudo! O Power Bi é excelente para fazer ETL simples, DAX / modelagem de dados, e visuais nem se fala… Mas para criar e treinar modelos de ML bem como fazer ETL’s complexas não!
Leonardo Karpinski
Tudo entendido?! Vamos seguir…
Bom, veremos que o Power Query mostrará a lista de tabelas que contém no nosso script e devemos expandir apenas futuro_todos_df:
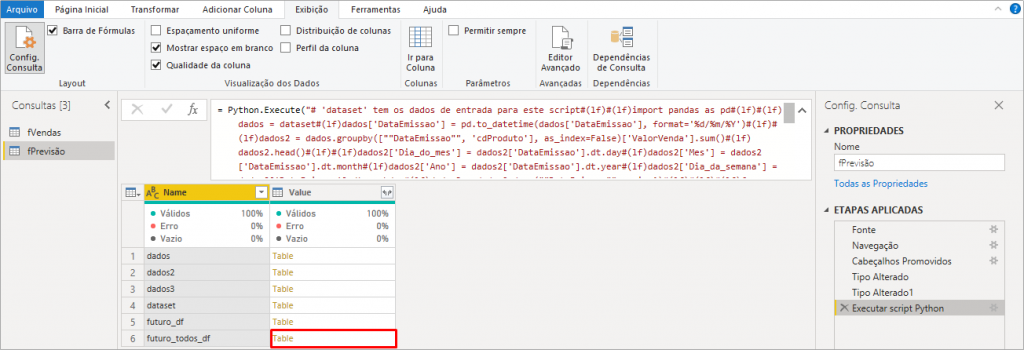
Após expandir a tabela clicando no nome Table em amarelo (referente à linha 6 da figura acima), teremos a etapa futuros_todos_df aplicada:
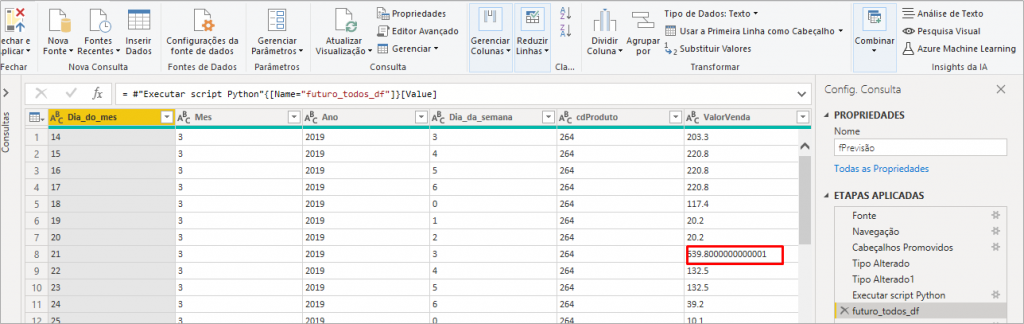
Observando o resultado após expansão de futuro_todos_df, caso o PBI tenha aplicado uma etapa de transformação “Tipo alterado2”, exclua essa etapa deixando apenas até essa etapa que aparece na figura acima. Veja que na linha 8 o número da coluna ValorVendas tem várias casas decimais. Isso pode acontecer quando o PBI lê algum número como texto. Iremos corrigir isso mudando o tipo alterado usando localidade, assim:
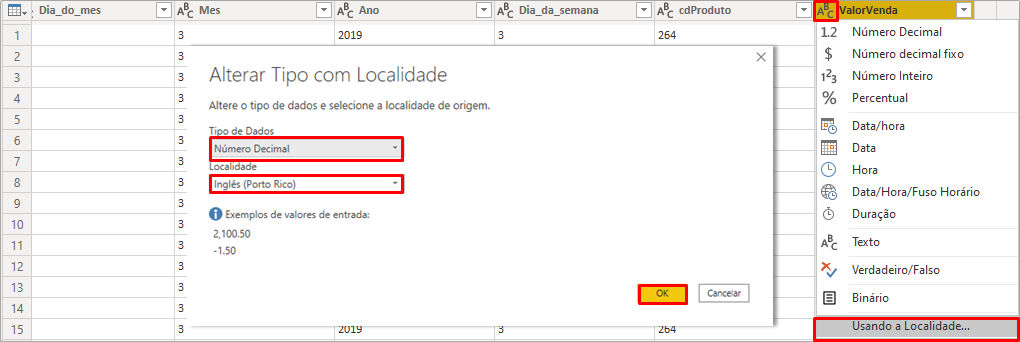
Verifique se as colunas: Dia_do_mes, Mes, Ano e Dia_da_Semana estão formatados como inteiro, caso não estejam modifique para Número decimal.
Não temos uma coluna de data nessa tabela, certo?! Precisamos construí-la e faremos isso através da mesclagem de colunas. Basta selecionar as colunas Dia_do_mes, Mes e Ano com a tecla CTRL ativada; clicar com o botão direito e selecionar a opção Mesclar colunas. Veja mais detalhes a seguir:
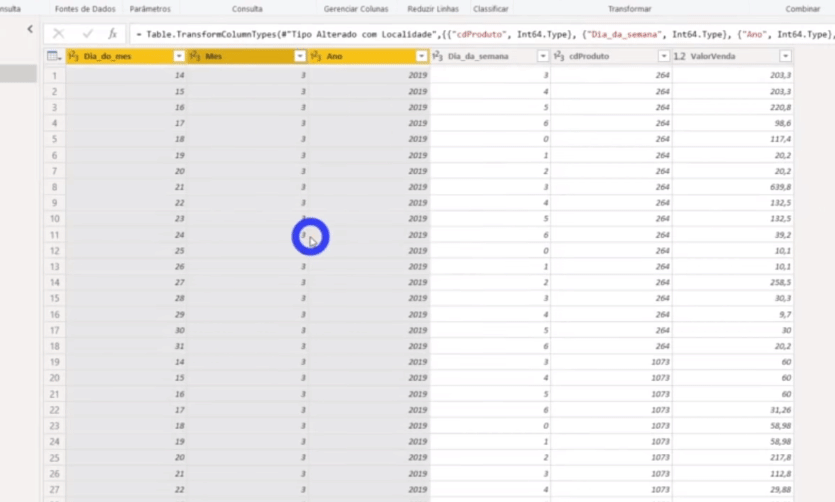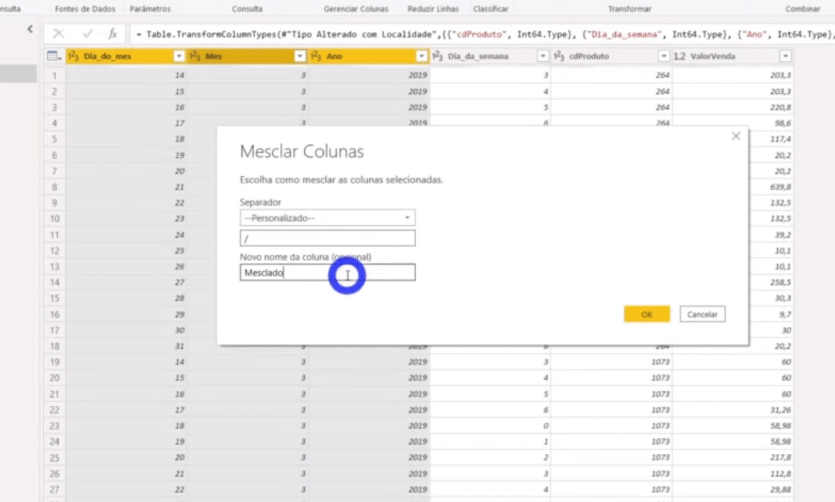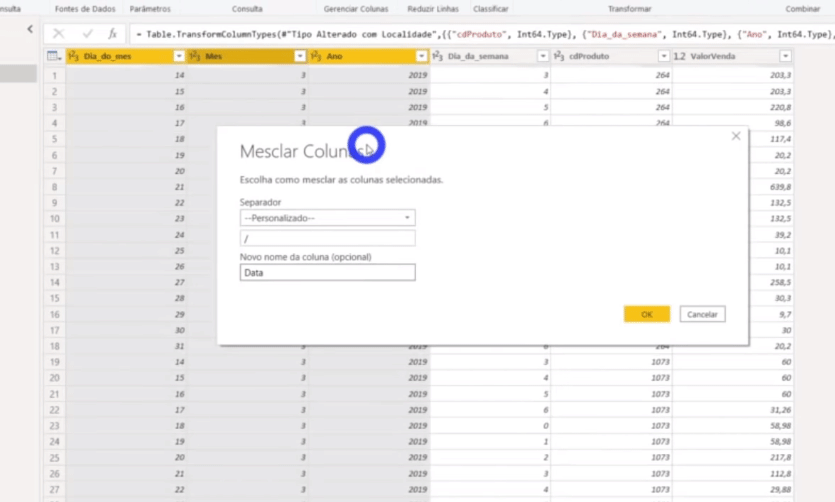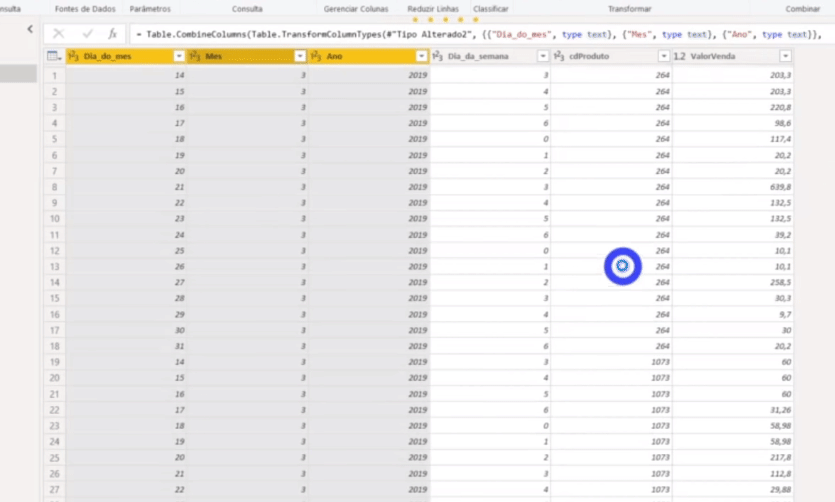
Não se esqueça de transformar essa coluna Data Previsão para o tipo Data, ok?!
Ah, esquecemos da tabela dProduto! Para criarmos essa tabela será fácil. Basta duplicarmos a fVendas, excluirmos todas as colunas exceto a coluna cdProduto (que deve estar formatada como Inteiro) e remover as duplicatas dessa coluna. Veja:
É muito importante termos esse cuidado de verificar se as colunas que iremos fazer os relacionamentos estão formatadas com o mesmo tipo numérico, beleza?! Então datas devem estar no formato de data, código de produto como inteiro e valores (de vendas) como decimais em todas as tabelas.
Agora, basta clicar em Fechar e aplicar no Power Query!
Criando a dCalendario via DAX
Vamos criar uma tabela dCalendario para relacionar todas as datas do nosso modelo. Para isso, basta ir em Modelagem e Nova Tabela.
Na barra de fórmulas digite:
dCalendario =CALENDAR ( DATE ( 2017; 01; 01 ); DATE ( 2019; 12; 31 ) )
Ao configurarmos os relacionamentos entre as tabelas, teremos o seguinte:
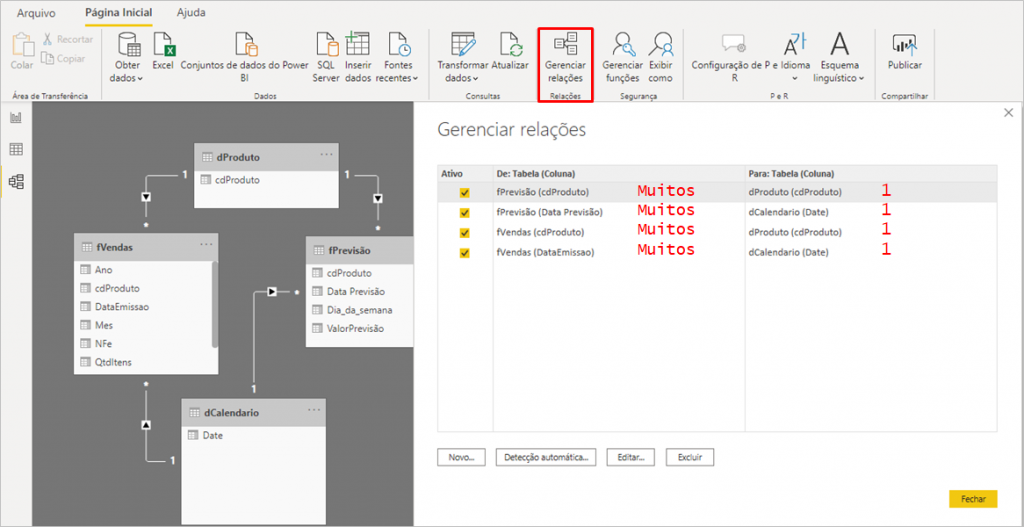
Visual
Chegou a hora de criarmos nosso primeiro gráfico!
Nosso intuito aqui é mostrar as possibilidades que temos de integrar Python com Power Bi, então não estaremos nos preocupando com o design e beleza dos gráficos, ok?!
Ah, um detalhe antes de adicionar nosso primeiro gráfico: editei o intervalo de datas que o modelo vai prever editando a etapa Executar script Python. Fique à vontade para alterar o intervalo da forma que preferir, beleza?!
Nosso gráfico ficou assim:
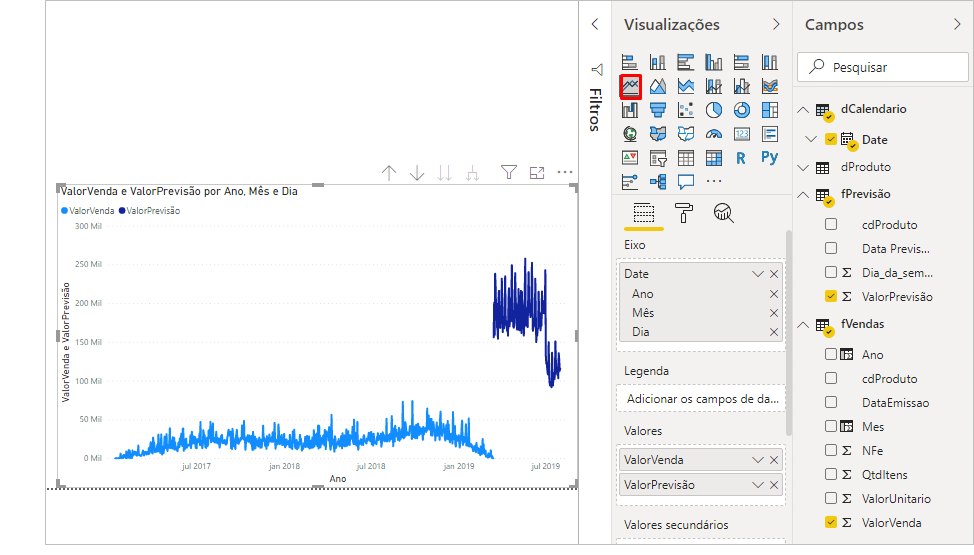
O gráfico que criamos é o Gráfico de Linhas. Você pode estar estranhando o comportamento da curva dos valores de previsão (em azul mais escuro). Fizemos esse exemplo bem rápido para fins de demonstração e temos várias técnicas que poderíamos implementar no script para melhorar esse modelo. Porém, se filtrarmos produto a produto, os valores passam a fazer um pouco mais de sentido, veja só:
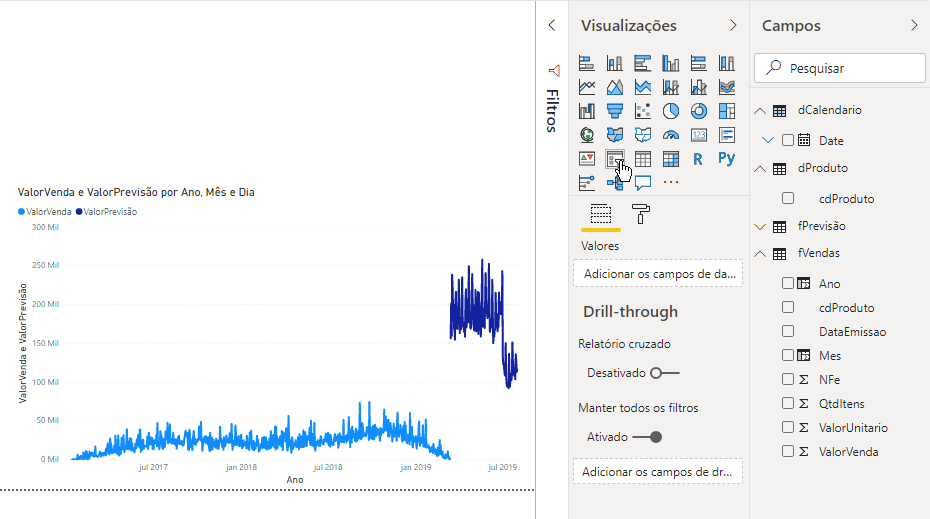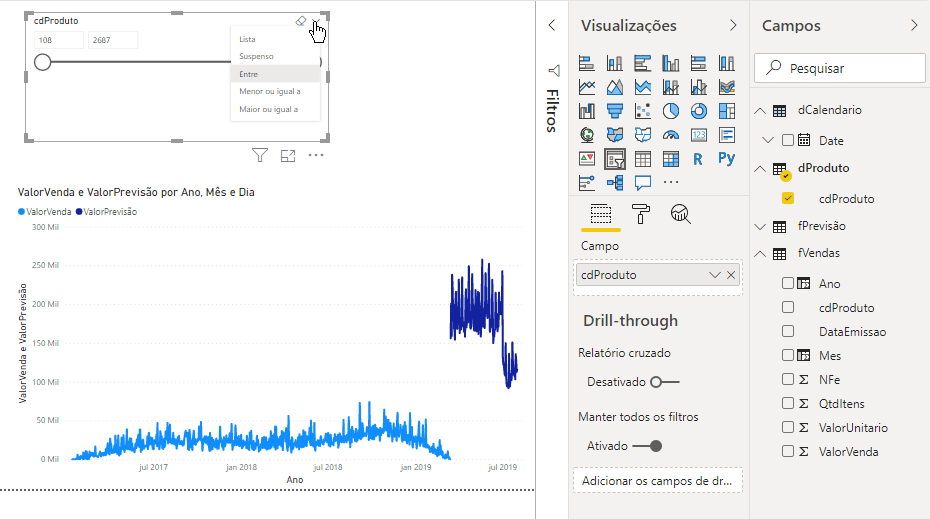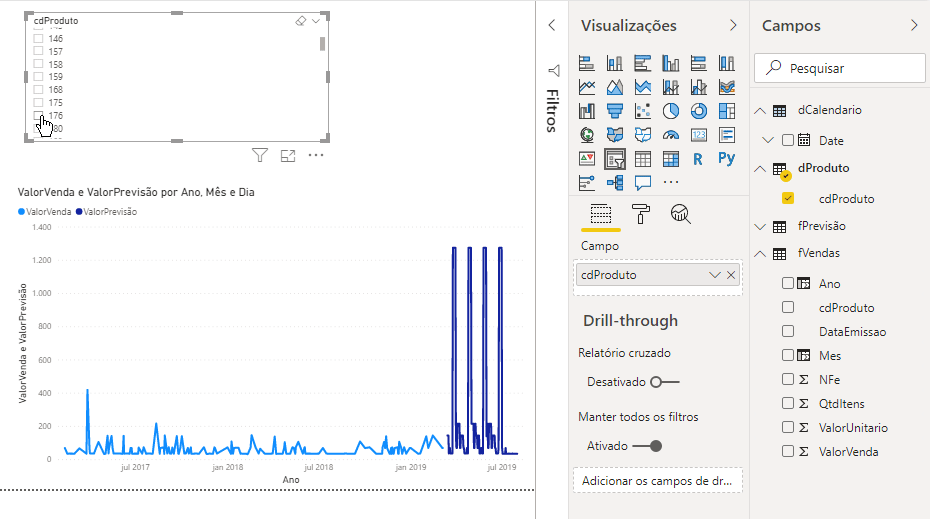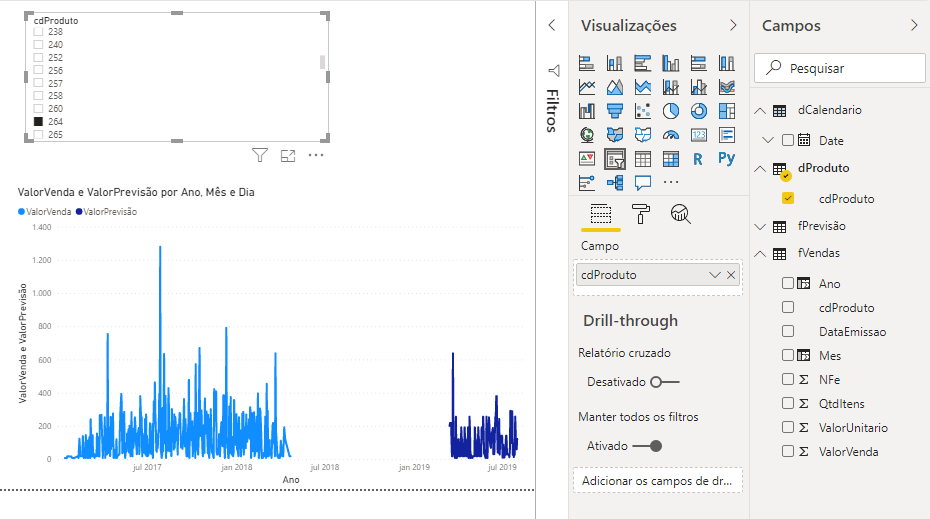
Agora, vamos para o próximo desafio: criar um visual com Python!
Desafio 2: Criando visuais com Python
Base de dados
Nossa base de dados consiste de uma tabela em Excel com dados de CHURN e possui as seguintes colunas:
Importe essa tabela para o Power Bi e vá para Relatórios (onde criaremos nossos gráficos).
Exemplo 1
A primeira coisa que faremos é clicar em Visual Python. Veja que aparecerá uma Editor de scripts abaixo da página:
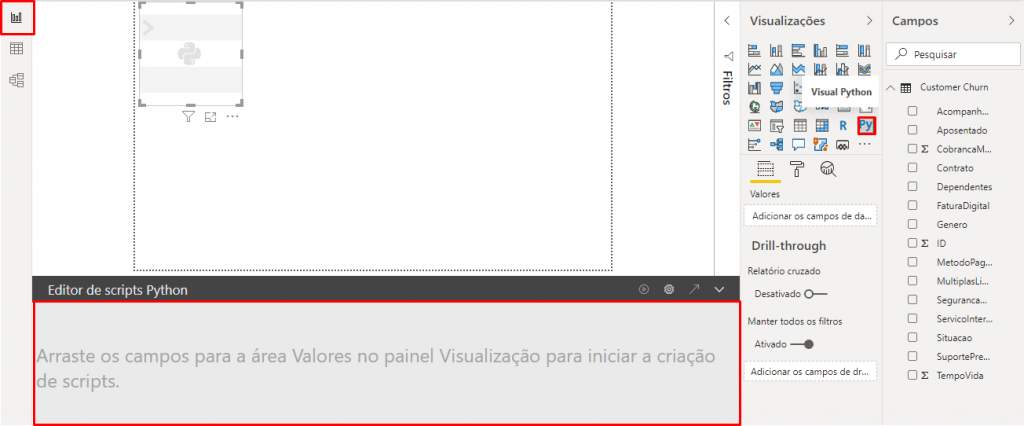
Quando adicionarmos as colunas nesse visual, automaticamente esse editor acrescentará algumas linhas, veja:
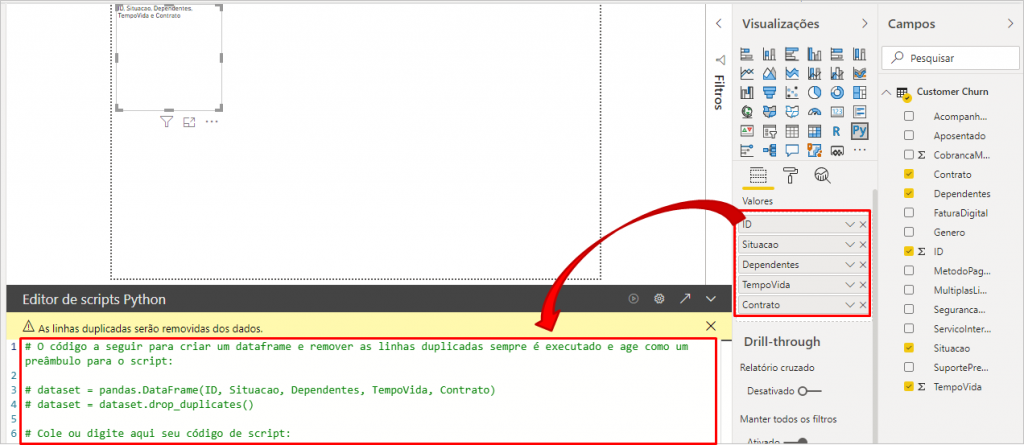
Agora adicionaremos esse código (de apenas 4 linhas) abaixo dessa linha 6 do Editor de scripts Python:
Comando Python:
import matplotlib.pyplot as plt import seaborn as sns sns.pairplot(dataset, vars=["TempoVida", "CobrancaMensal"], hue="Situacao") plt.show()
Após aplicar esse código no editor e clicar no botão de “play”, teremos esse visual:
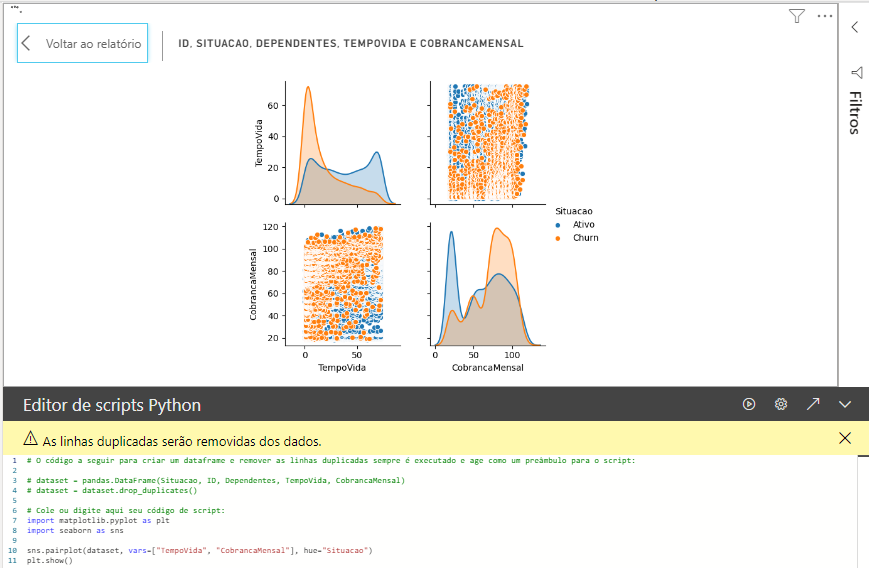
Vamos para um outro exemplo!
Exemplo 2
Dessa vez utilizaremos as colunas: ID, CobrancaMensal, TempoVida, Situacao e SevicoInternet. Copie e cole o código abaixo no editor:
Comando Python:
import numpy as np import seaborn as sns import matplotlib.pyplot as plt sns.set(style="darkgrid") tips = dataset g = sns.FacetGrid(tips, row="Situacao", col="ServicoInternet", margin_titles=True) bins = np.linspace(0, 60, 13) g.map(plt.hist, "CobrancaMensal", color="steelblue", bins=bins) plt.show()
Para esse visual utilizei o código que está nesse site: https://seaborn.pydata.org/examples/faceted_histogram.html e realizei os ajustes necessários. Veja o que modifiquei do código original:
Dica:
Utilizei o site https://seaborn.pydata.org/examples/index.html para busar o código de cada visual (e suas respectivas bibliotecas).
Agora, vejam que legal! Conseguimos adicionar um visual nativo do Power Bi e realizar filtros no gráfico em Python!
Veja abaixo que se adicionarmos um gráfico de barras, por exemplo, e selecionarmos uma barra, conseguiremos ‘filtrar’ os gráficos do Python (mas o contrário não é possível):
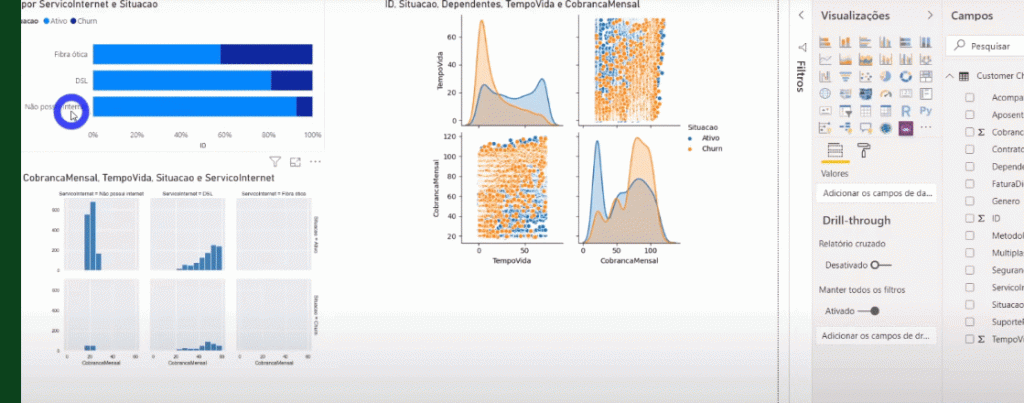
Lembrando que para códigos em R é a mesma coisa, só muda a sintaxe – que é específica de cada linguagem, beleza?!
Finalizamos então o conteúdo de hoje! Conseguimos mostrar em detalhes como funciona essa integração Python + Power Bi em duas aplicações.
Espero que tenham gostado! Até mais!
Um abraço,
Leonardo!


